MySQL笔记
先了解下
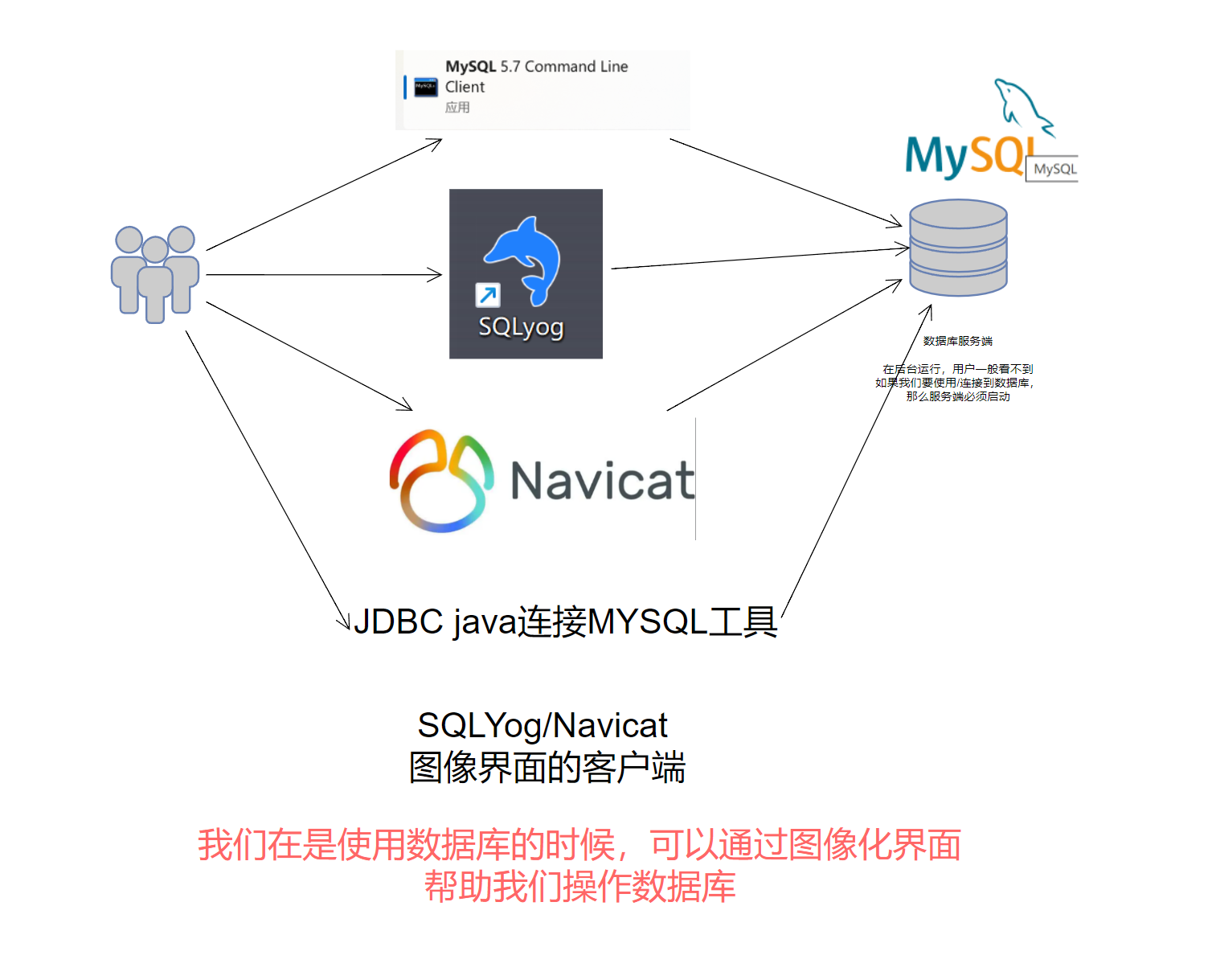
我们使用数据库的方式
用户 ----> 客户端工具 -----> MySQL服务端
卸载了[非必须]
需要卸载软件的时候看这里
安装方式
1、MYSQL下载地址
| 社区免费版本的下载地址 |
|---|
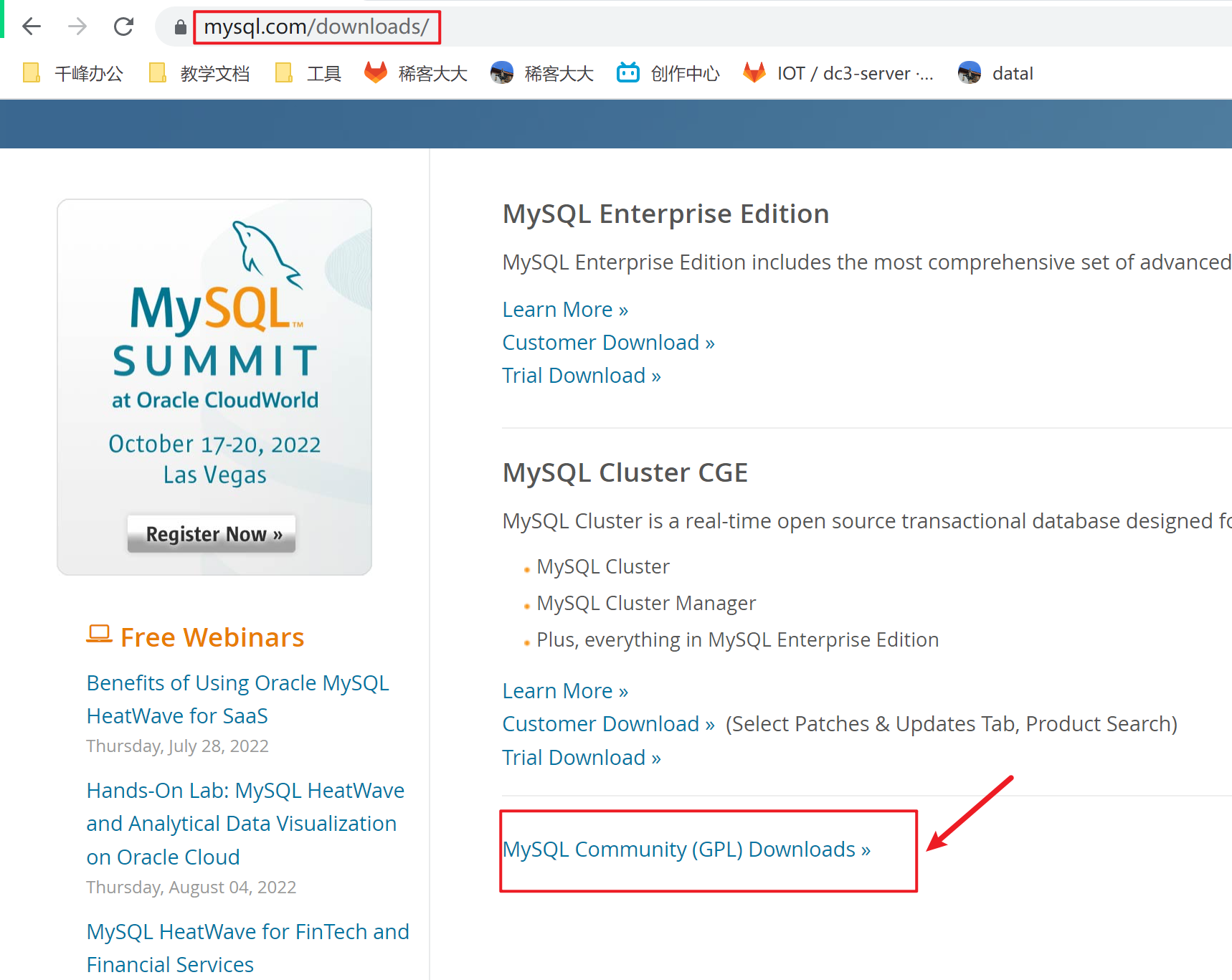 |
| Windows安装器的下载 |
|---|
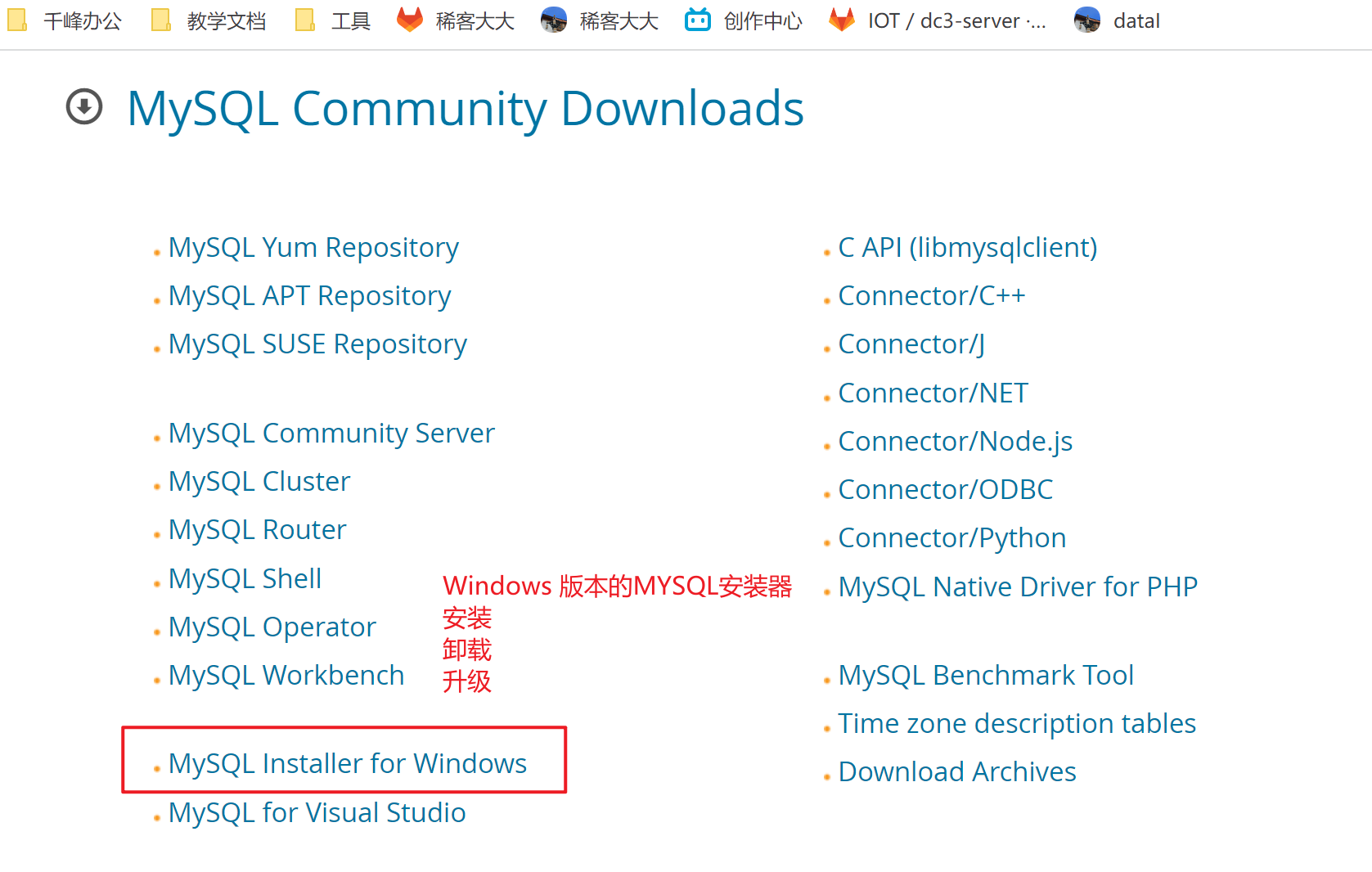 |
5.7版本的下载地址
| 安装器的地址 |
|---|
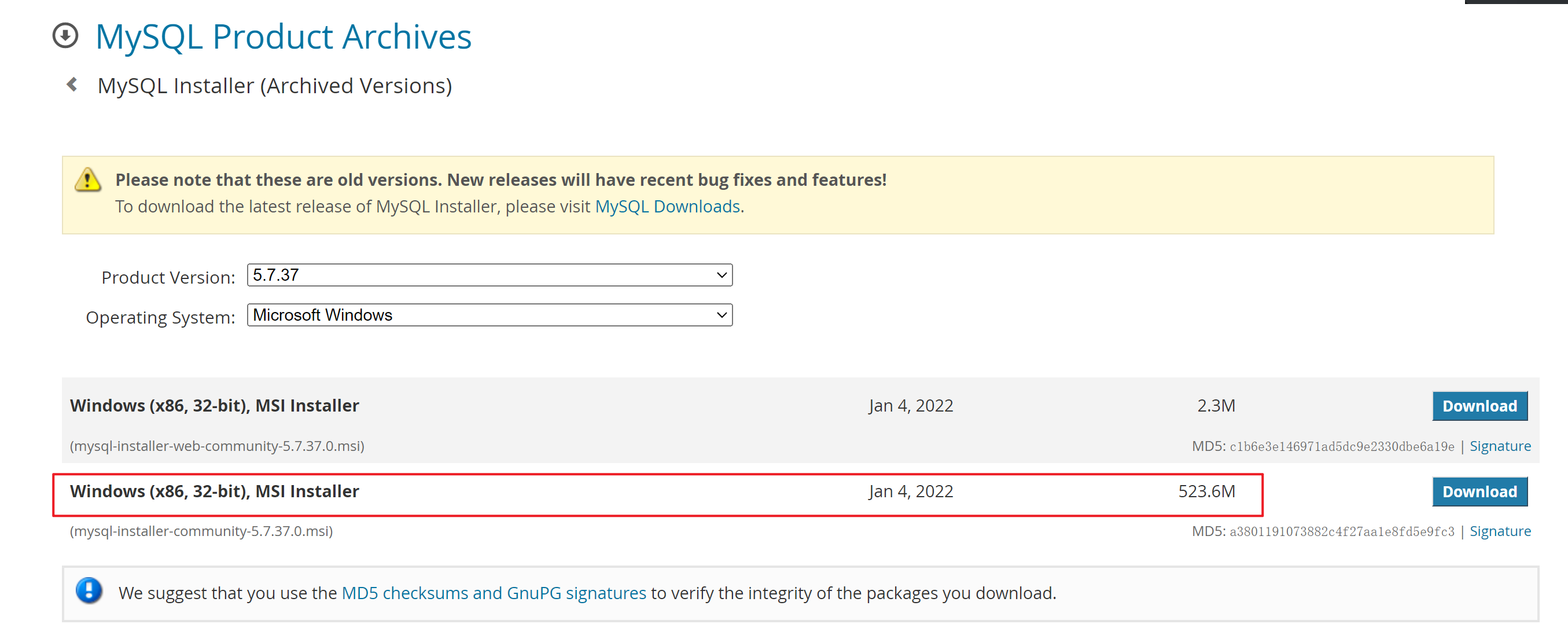 |
点击上面的连接进行下载,下载完成后可以进行双击安装
image-20220722112024241

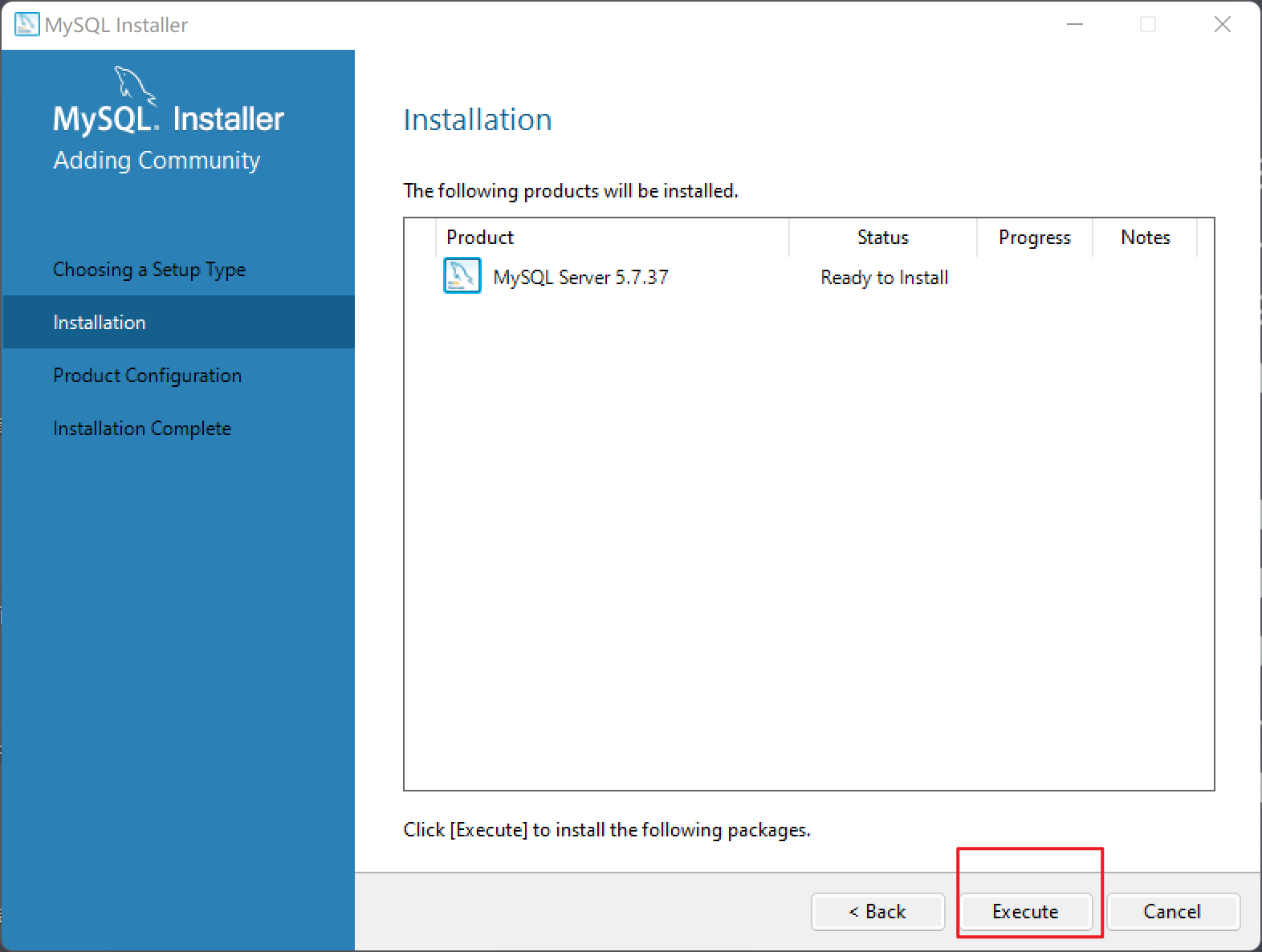
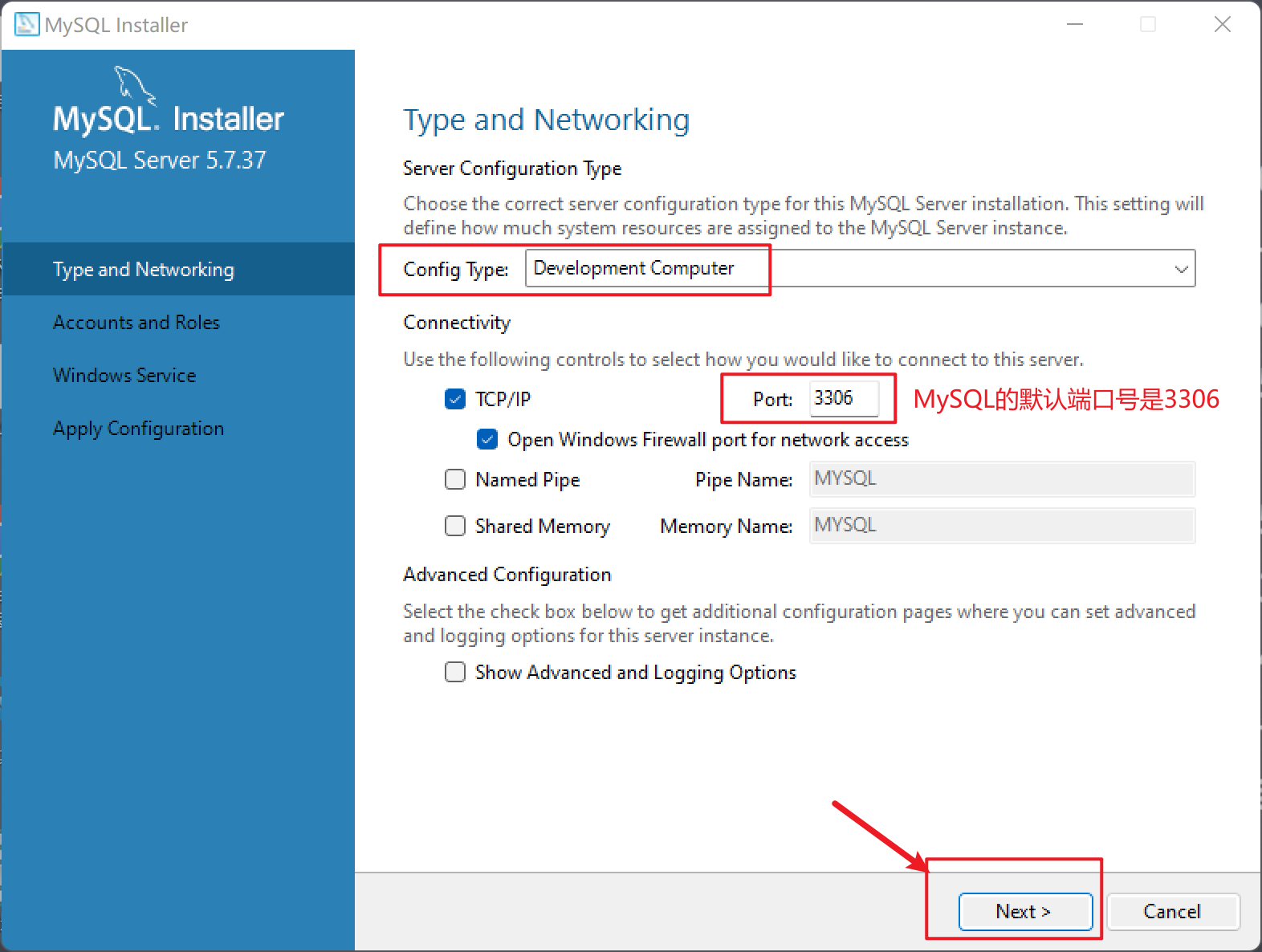
安装步骤
| 安装过程 |
|---|
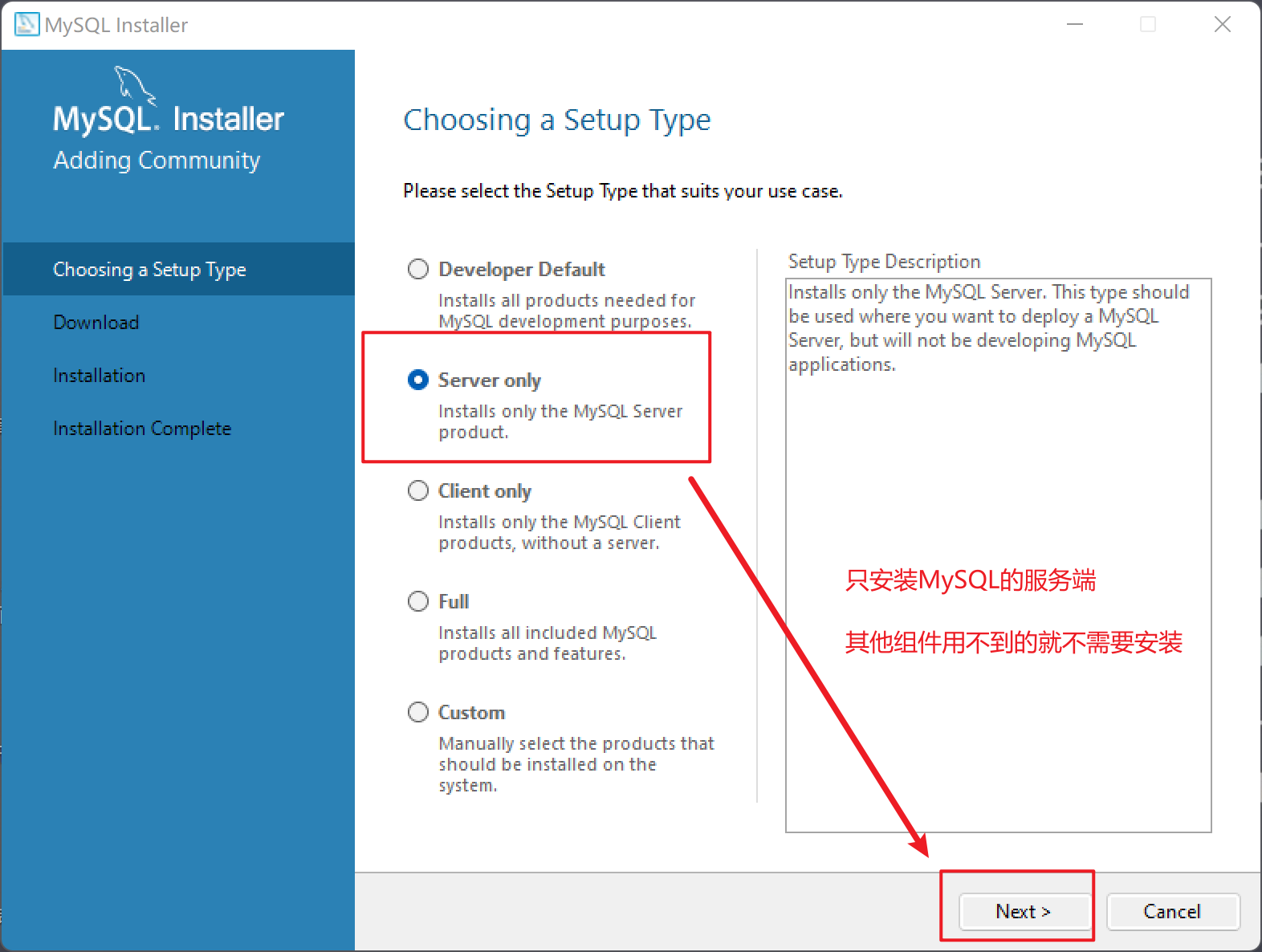 |
 |
| 下一步,下一步。。。 |
 |
| 设置密码 |
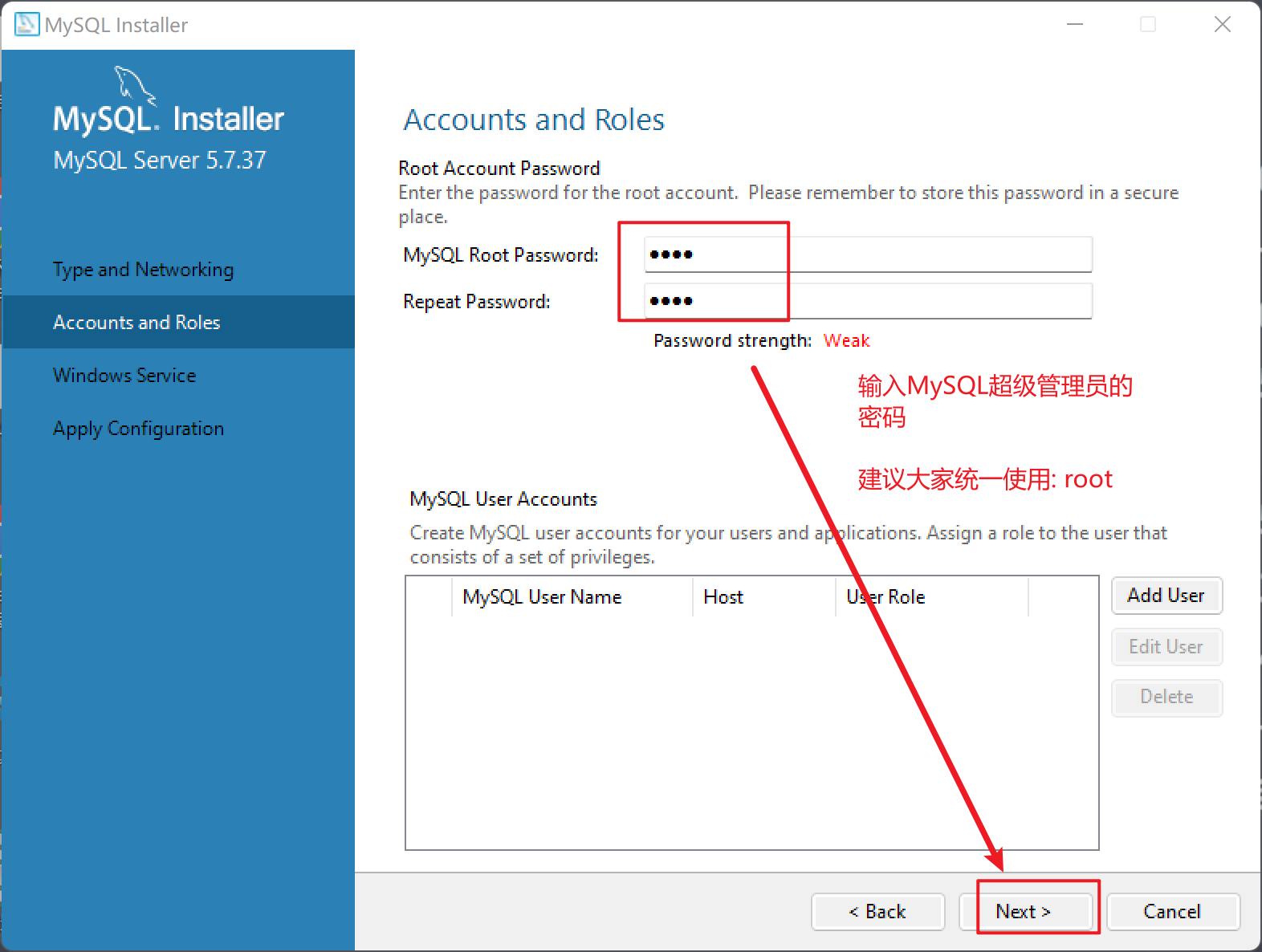 |
| 安装windows服务的 |
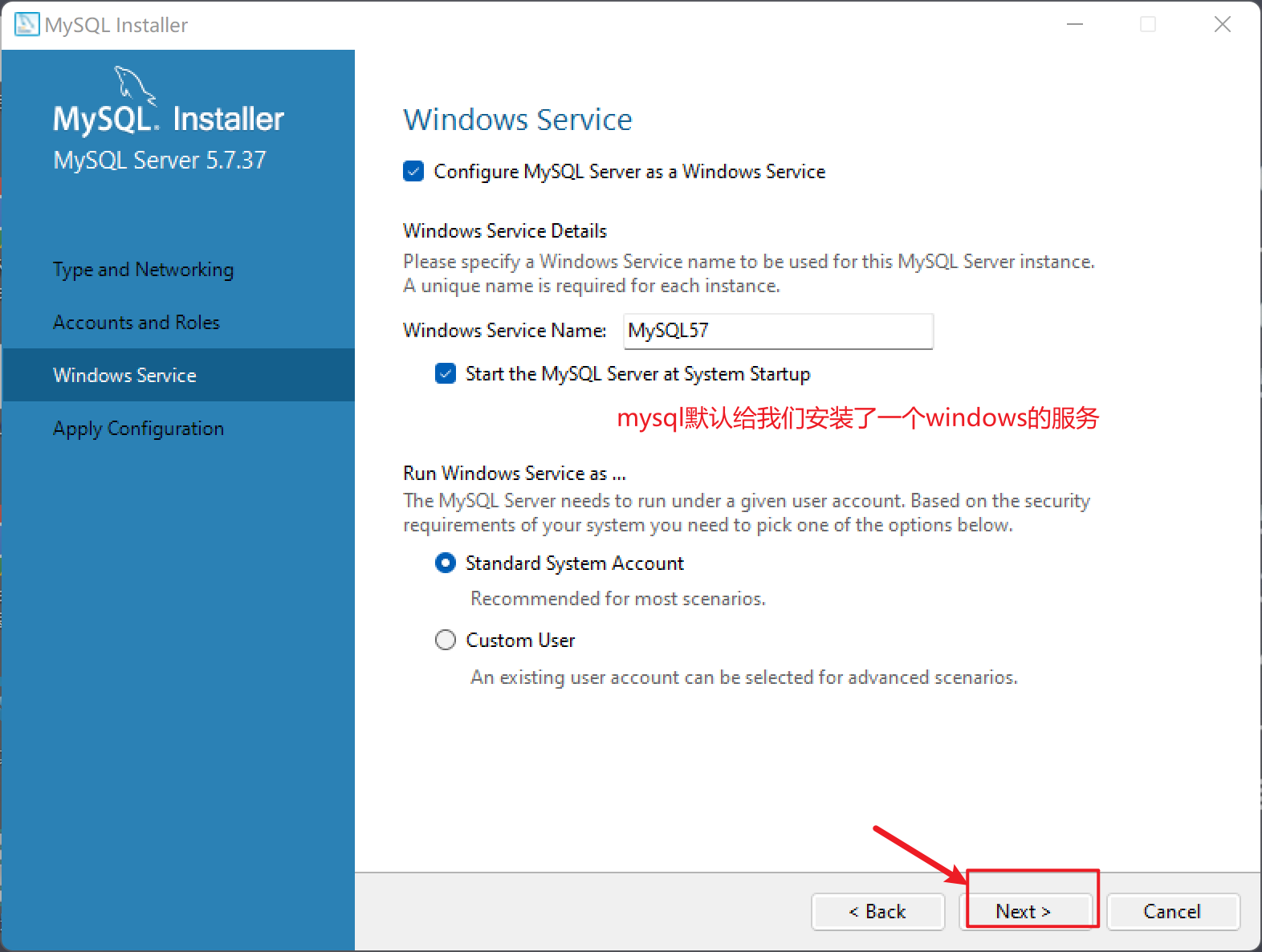 |
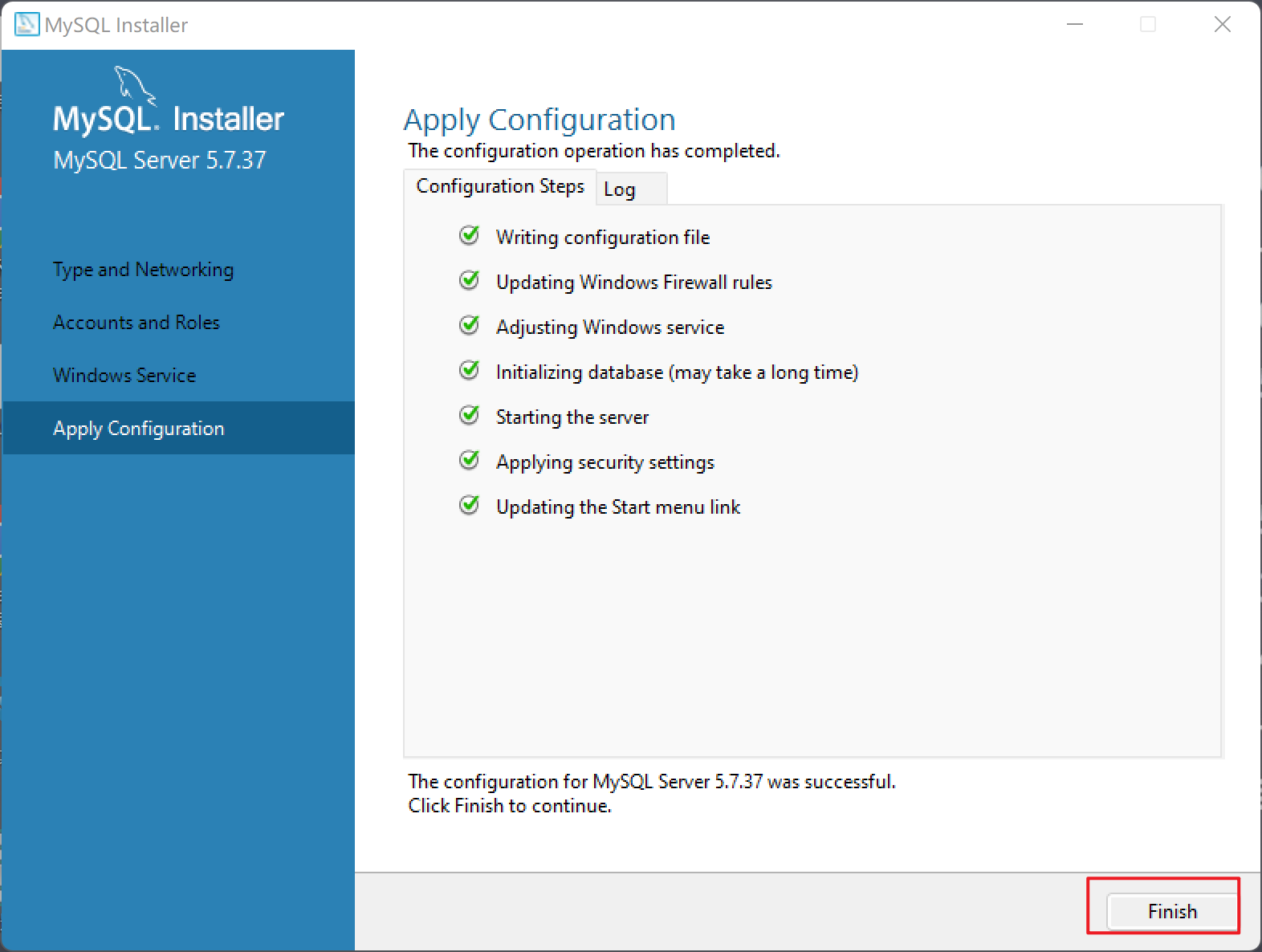 |
| 到这里已经安装成功了!恭喜你,可以进入MySQL的学习了! |
MySQL服务
| 查看MySQL的服务 |
|---|
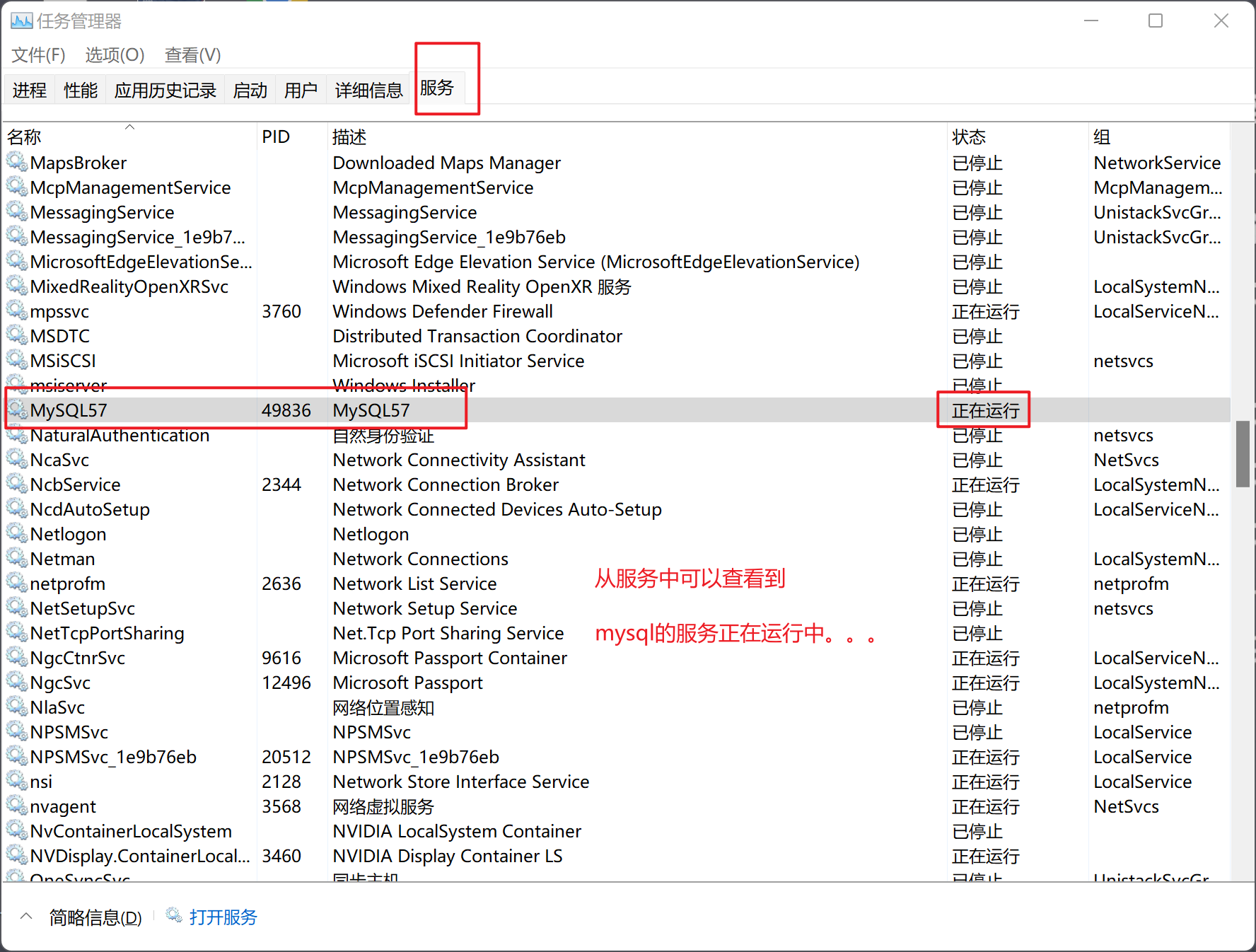 |
默认的安装位置
| 默认是安装在C盘的Program Files/MySQL目录下,建议安装在默认位置 |
|---|
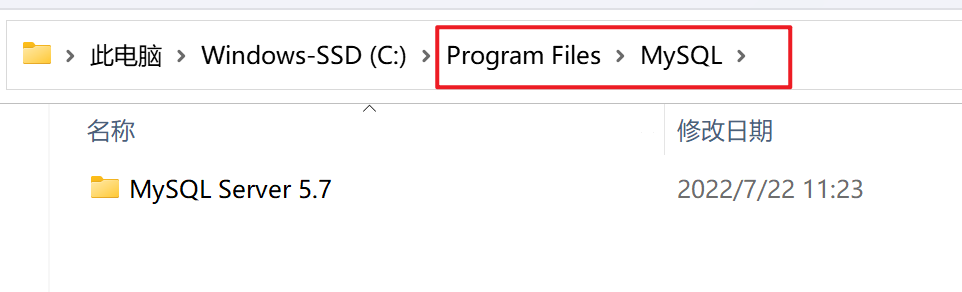 |
| 默认的数据保存位置 |
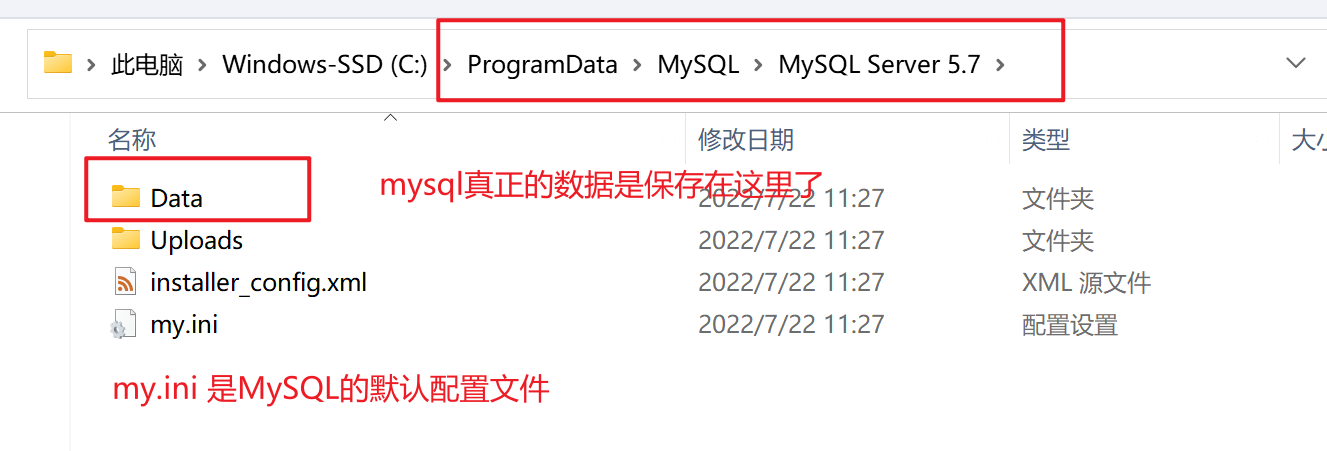 |
SQLYog客户端的安装
下一步,下一步,傻瓜式安装..
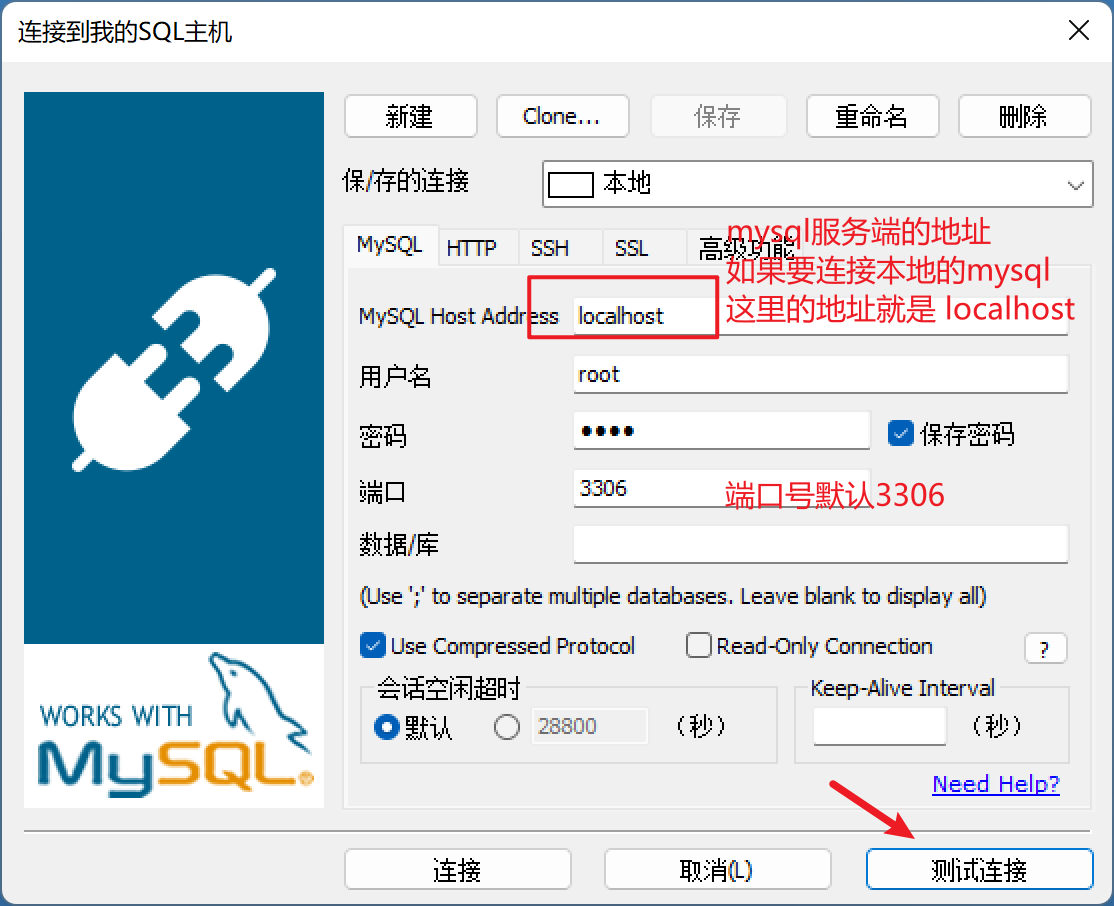
使用客户端连接数据库
1、双击Sqlyog快捷方式
2、输入 服务端地址、用户名、密码、端口号
3、测试连接,之后就不用每次都点击测试连接
4、直接连接
| 输入数据库信息 |
|---|
 |
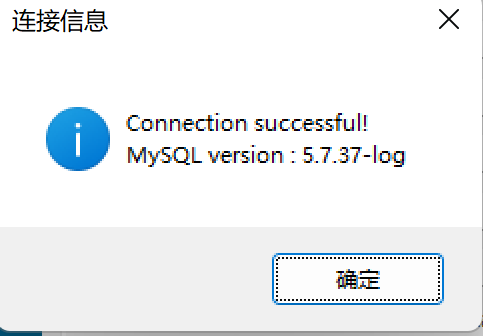
| 测试连接,看到这个界面说明连接成功 |
 |
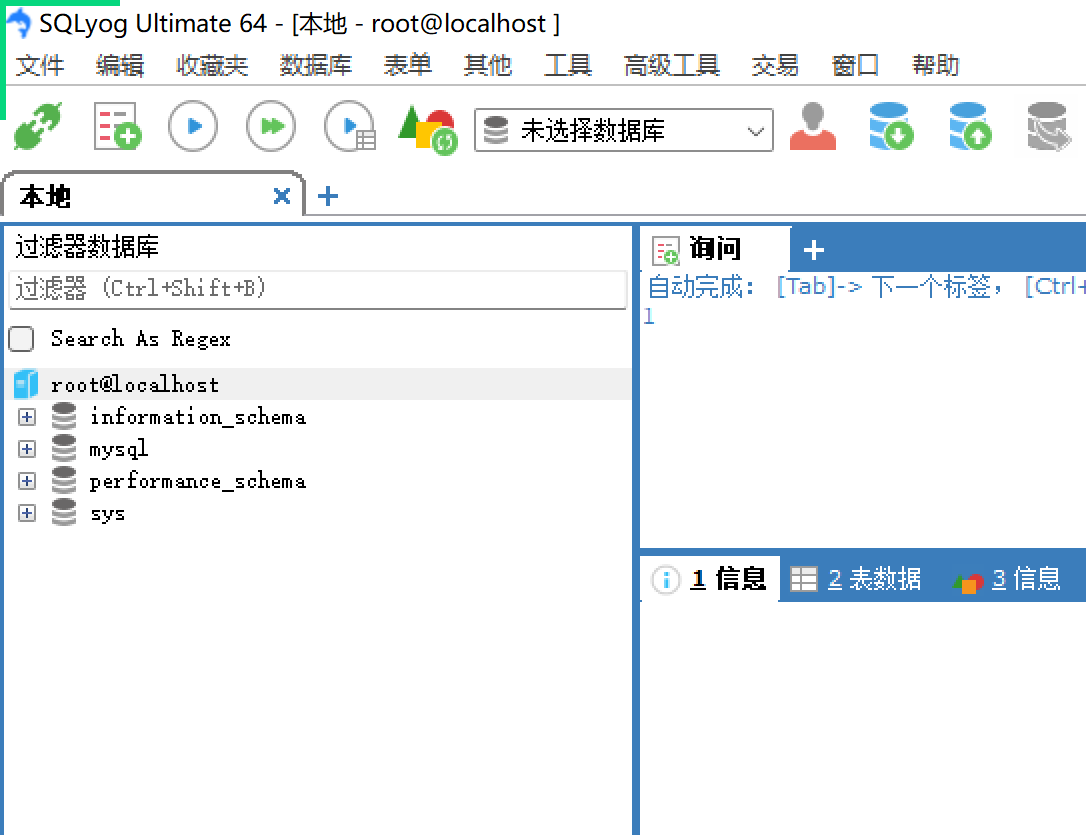
| 点击连接后,进入这个界面,就可以愉快的使用MYSQL了! |
 |
使用命令行的方式连接
连接命令
mysql -uroot -p回车以后再输入密码image-20220722144339913
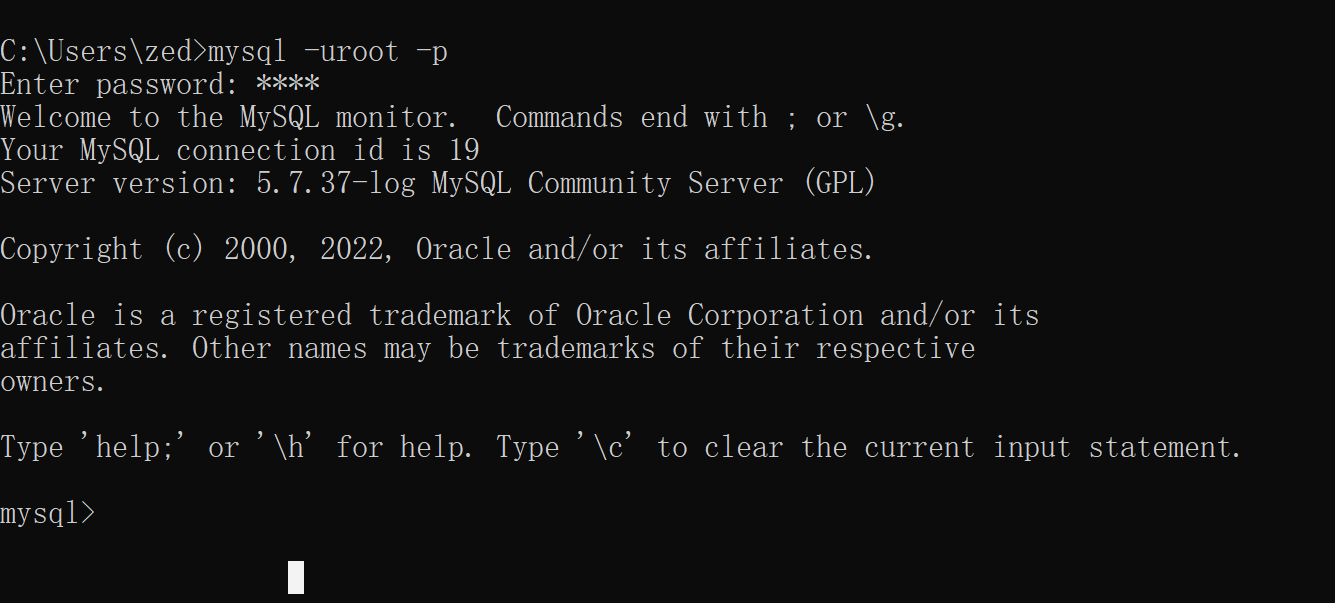
查看mysql中都有哪些数据库
show databases;
db 数据库 database
dba 数据库管理员 database administrator
image-20220722144616163

切换[使用]哪个数据库
use mysql;use 数据库名字,就切换到指定的数据库了image-20220722144729251

查看当前数据库中,都有哪些表
show tables;image-20220722144812221
退出mysql提示符
exitimage-20220722144853299
mysql 内置的系统函数
-- 使用password函数对root字串进行加密
-- *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B
SELECT PASSWORD('root');
数据库的介绍
DBMS:数据库管理系统
DBA:数据库管理员
RDBMS: 关系型数据库管理系统 mysql oracle Db2 SqlServer
常用的关系型数据库:Oracle:企业级的大型数据库 MySQL开源免费的 SqlServer 达梦
非关系型数据库:ElasticSearch 搜索引擎 Redis key-value缓存数据库 MongoDB 文档型数据库
图数据库:Neo4j 保存数据:保存的格式是节点和节点之间的连线 [推荐引擎,知识图谱]
MySQL配置文件
在MySQL安装目录中找到my.ini文件,并打开my.ini文件查看几个常用配置参数
| 参数 | 描述 |
|---|---|
| default-character-set | 客户端默认字符集 |
| character-set-server | 服务器端默认字符集 |
| port | 客户端和服务器端的端口号 |
| default-storage-engine | MySQL默认存储引擎 INNODB |
安装郭MySQL以后,可以修改下配置文件,修改后是全局生效的
主要修改的地方,就是字符编码【客户端的字符编码+服务端的字符编码】,建议全部修改为utf8编码
因为MySQL安装后默认的字符编码是Latin编码,西欧编码[ISO-8859-1]
# client客户端的配置信息
[client]
# 端口号默认是3306
port=3306
[mysql]
# 修改客户端的编码为utf8
default-character-set=utf8
# 服务端的配置信息
[mysqld]
# 服务端的编码修改为utf8
character-set-server=utf8
导入SQL脚本
| 导入脚本 |
|---|
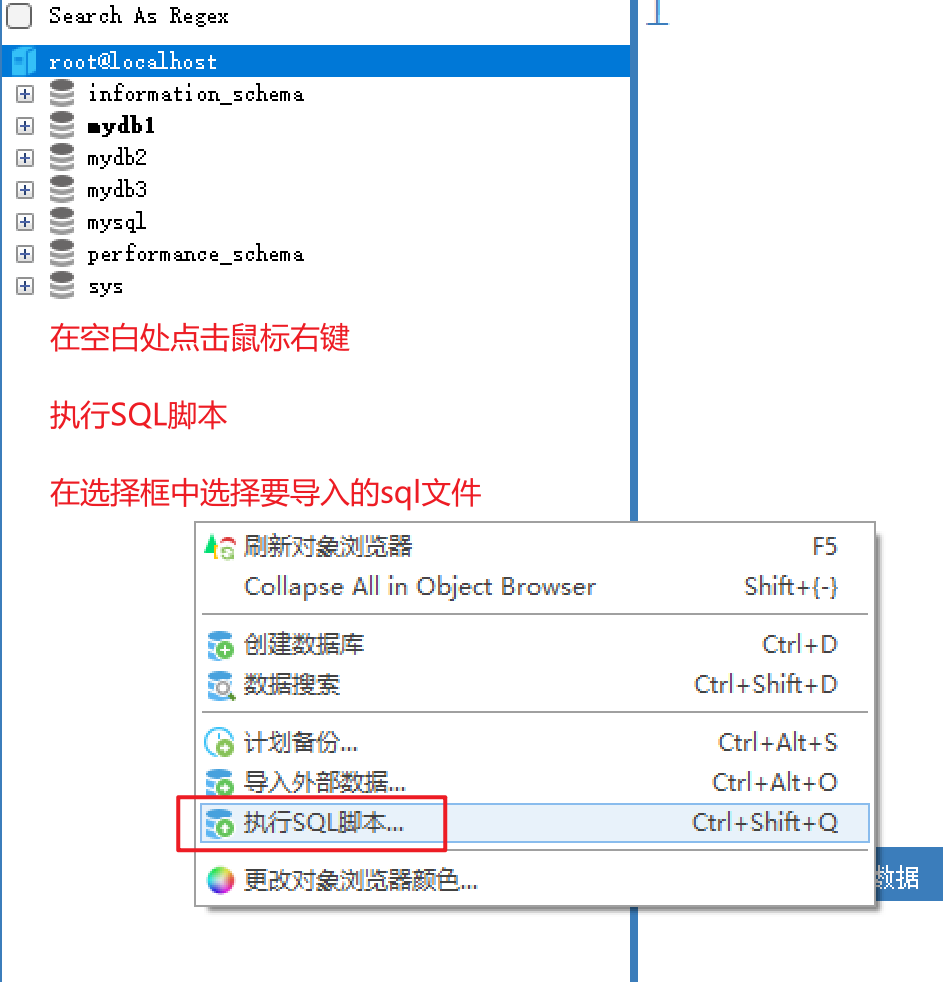 |
| 执行脚本 |
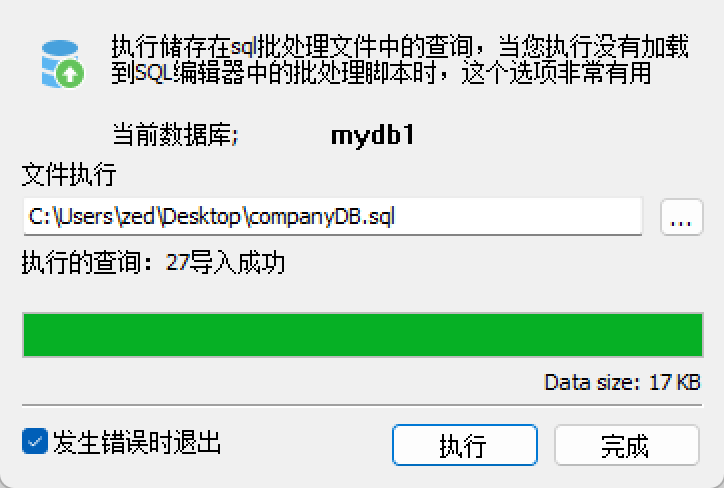 |
执行完成后,就可以在左侧的数据库浏览窗口中看到数据库了。
数据库表的基本结构
表是由很多行组成(一行就表示一条数据),每一行都由很多列组成。
一列就是一个字段【属性】
SQL语句
SQL:结构化查询语言,管理数据还可以管理数据库。
- 创建create/修改alter/删除drop - 库/表/视图/存储过程 【跟数据库对象有关的】DCL【数据定义语言】
- 新增insert/更新update/删除delete/查询select CRUD 【跟数据操作相关的】DML 【数据操纵语言】
创建修改删除数据库
-- 创建数据库的语法
-- 直接创建数据库
CREATE DATABASE mydb1;
CREATE DATABASE mydb2;
-- 创建数据库时同时指定字符编码
CREATE DATABASE mydb3 CHARACTER SET utf8;
-- 数据库不存在时创建[如果这个库已经存在了就什么都不干]
CREATE DATABASE IF NOT EXISTS mydb4;
-- 查看数据库创建信息
SHOW CREATE DATABASE mydb3;
-- 修改数据库[修改字符编码]
ALTER DATABASE mydb3 CHARACTER SET utf8;
-- 删除数据库
DROP DATABASE mydb4;
-- 查看当前正在使用哪个数据库
SELECT DATABASE();
-- 切换数据库
USE mydb1;
数据查询【重点】
语法: select 列名 from 表名;
select : 查询 from 从哪
*星号表示一行中的所有列;
基本查询
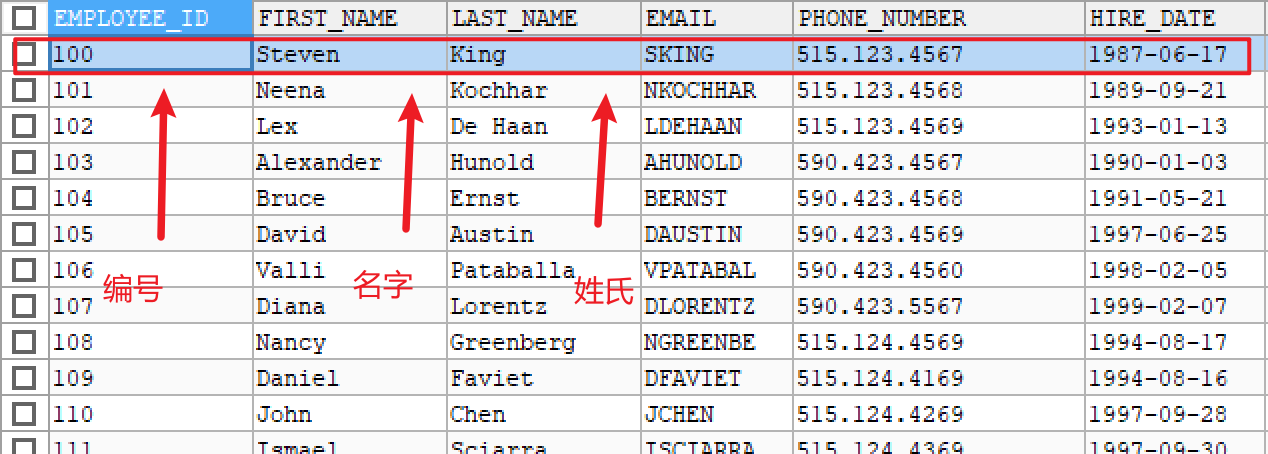
-- 从t_employees表中查询所有数据
-- * 的意思是一行中的所有列
SELECT * FROM t_employees;
-- 只返回指定的列数据
SELECT EMPLOYEE_ID,FIRST_NAME,EMAIL FROM t_employees;
对列进行运算
-- 查询工资[对查询到的列数据可以进行运算]
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY,SALARY/100 FROM t_employees;
mysql中数值类型字串的隐式类型转换
# mysql中隐式的类型转换 1231/124 SELECT '123'+1 # 124 SELECT '123abc'+1 # 如果是纯字串,参与数学运算时,会转换为0再参与运算 SELECT 'abc'+1
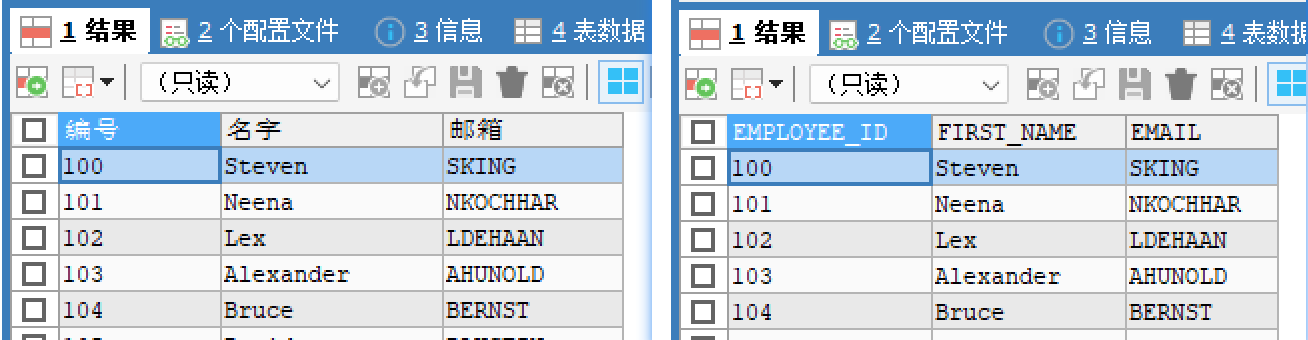
列的别名
-- 对查询到的列数据起个别名[小名]
-- 在列名后面指定别名
SELECT EMPLOYEE_ID 编号,FIRST_NAME 名字,EMAIL 邮箱 FROM t_employees;
-- as 起别名的,可以省略
SELECT EMPLOYEE_ID AS 编号,FIRST_NAME AS 名字,EMAIL AS 邮箱 FROM t_employees;
-- 别名中如果有空格,需要添加引号括起来[单引号,双引号都行]
SELECT EMPLOYEE_ID '编 号',FIRST_NAME '名 字',EMAIL '邮 箱' FROM t_employees;
列去重
-- 查看有重复数据的列
SELECT `DEPARTMENT_ID` FROM `t_employees`;
-- 对查询到的部门去重[DISTINCT:去重]
SELECT DISTINCT `DEPARTMENT_ID` FROM `t_employees`;
注意:列名、表名、数据库名字中如果正好是mysql的关键字,那么需要对名字加上撇号 `
如果列名、表名、数据库名字不是关键字,加不加撇号都可以!
列排序
语法: SELECT 列名 FROM 表名 [ORDER BY 排序列 排序规则]
| 排序规则 | 描述 |
|---|---|
| ASC | 对前面排序列做升序排序 |
| DESC | 对前面排序列做降序排序 |
可以对字串进行排序,也可以对数值进行排序
可以升序也可以降序
-- 语法: SELECT 列名 FROM 表名 ORDER BY 排序列 [排序规则]
-- ASC 升序号【默认值,可以省略】 desc:降序【不能省略了】
SELECT FIRST_NAME,LAST_NAME,SALARY FROM t_employees ORDER BY salary DESC;
字串类型排序 默认是按自然排序[0-9 a-z ]
SELECTEMPLOYEE_ID,FIRST_NAME
FROMt_employees
ORDER BYFIRST_NAMEASC
依据单列排序
#查询员工的编号,名字,薪资。按照工资高低进行降序排序。
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`
FROM `t_employees`
ORDER BY `SALARY`;
依据多列进行排序
#查询员工的编号,名字,薪资。按照工资高低进行升序排序(薪资相同时,按照编号进行升序排序)。
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`
FROM `t_employees`
ORDER BY `SALARY`,`EMPLOYEE_ID`;
条件查询
语法:SELECT 列名 FROM 表名 WHERE 条件
SELECT * FROM
t_employeesWHERE 1=2 条件不成立,一条数据都没有返回SELECT * FROM
t_employeesWHERE 1=1 条件永远成立,返回返回所有数据
| 关键字 | 描述 |
|---|---|
| WHERE 条件 | 在查询结果中,筛选符合条件的查询结果,条件为布尔表达式 |
等值判断(=)
#查询薪资是11000的员工信息(编号、名字、薪资)
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`
FROM `t_employees`
WHERE `SALARY`=11000
逻辑判断(and、or、not)
#查询薪资是11000并且提成是0.30的员工信息(编号、名字、薪资)
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`,`COMMISSION_PCT`
FROM `t_employees`
WHERE `SALARY`=11000 AND `COMMISSION_PCT`=0.30
不等值判断(> 、< 、>= 、<= 、!= 、<>)
!= <> 都表示不等于的意思
#查询员工的薪资在6000~10000之间的员工信息(编号,名字,薪资)
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`,`COMMISSION_PCT`
FROM `t_employees`
WHERE `SALARY`>=6000 AND `SALARY`<=10000
# 工资查过10000的
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`,`COMMISSION_PCT`
FROM `t_employees`
WHERE `SALARY`>10000
# 工资不等于10000 `SALARY`<>10000 或者使用 `SALARY`!=10000
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`,`COMMISSION_PCT`
FROM `t_employees`
WHERE `SALARY`<>10000
区间判断(between and)
#查询员工的薪资在6000~10000之间的员工信息(编号,名字,薪资)
#[包含边界]
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`,`COMMISSION_PCT`
FROM `t_employees`
WHERE `SALARY` BETWEEN 6000 AND 10000
NULL 值判断(IS NULL、IS NOT NULL)
IS NULL
列名 IS NULL
IS NOT NULL
列名 IS NOT NULL
#查询没有提成的员工信息(编号,名字,薪资 , 提成)
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`,`COMMISSION_PCT`
FROM `t_employees`
WHERE `COMMISSION_PCT` IS NULL
# 有提成的员工
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`,`COMMISSION_PCT`
FROM `t_employees`
WHERE `COMMISSION_PCT` IS NOT NULL
枚举查询( IN (值 1,值 2,值 3 ) )
#查询部门编号为70、80、90的员工信息(编号,名字,薪资 , 部门编号)
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`,`DEPARTMENT_ID`
FROM `t_employees`
WHERE `DEPARTMENT_ID` IN(70,80,90)
# 使用or条件也可以
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`SALARY`,`DEPARTMENT_ID`
FROM `t_employees`
WHERE `DEPARTMENT_ID`=70 OR `DEPARTMENT_ID`=80 OR `DEPARTMENT_ID`=90
模糊查询
LIKE _ (单个任意字符)
列名 LIKE '张_'
LIKE %(任意长度的任意字符)
列名 LIKE '张%'
#查询名字以"L"开头的员工信息(编号,名字,薪资 , 部门编号)
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`LAST_NAME`
FROM `t_employees`
WHERE `FIRST_NAME` LIKE 'J%'
#查询名字以"L"开头并且长度为4的员工信息(编号,名字,薪资 , 部门编号)
SELECT `EMPLOYEE_ID`,`FIRST_NAME`,`LAST_NAME`
FROM `t_employees`
WHERE `FIRST_NAME` LIKE 'J___'
撇号` 和引号 【单引号】【双引号】的区别和使用场景:
撇号使用在数据库名字、表名、字段名,在这些地方使用,如果数据库名字/表名/字段名出现mysql语法中的关键字了,那么这些名字就需要使用撇号括起来。
引号是针对数据的,对要查询的字串类型的数据使用引号
分支结构查询
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
WHEN 条件3 THEN 结果3
ELSE 结果
END
#查询员工信息(编号,名字,薪资 , 薪资级别<对应条件表达式生成>)
SELECT `EMPLOYEE_ID` 编号,`FIRST_NAME` 姓名,`SALARY` 工资,
CASE
WHEN salary>=10000 THEN 'A'
WHEN salary>=8000 AND salary <10000 THEN 'B'
WHEN salary>=6000 AND salary <8000 THEN 'C'
WHEN salary>=4000 AND salary <6000 THEN 'D'
ELSE 'E'
END 级别
FROM `t_employees`
时间查询
语法:SELECT [时间函数(参数列表])
| 时间函数 | 描述 |
|---|---|
| SYSDATE() | 当前系统时间(日、月、年、时、分、秒) |
| CURDATE() | 获取当前日期 |
| CURTIME() | 获取当前时间 |
| WEEK(DATE) | 获取指定日期为一年中的第几周 |
| YEAR(DATE) | 获取指定日期的年份 |
| HOUR(TIME) | 获取指定时间的小时值 |
| MINUTE(TIME) | 获取时间的分钟值 |
| DATEDIFF(DATE1,DATE2) | 获取DATE1 和 DATE2 之间相隔的天数 |
| ADDDATE(DATE,N) | 计算DATE 加上 N 天后的日期 |
# 时间函数
# NOW返回当前时间
SELECT NOW();
# 返回系统时间
SELECT SYSDATE();
# now() 和 sysdate()的区别
SELECT NOW(),SLEEP(2),NOW();
SELECT SYSDATE(),SLEEP(2),SYSDATE();
# 获取当前日期
SELECT CURDATE();
# 获取当前时间
SELECT CURTIME();
# year,month,day,hour,MINUTE,SECOND,WEEK
# 返回指定日期的当年的第几周
SELECT WEEK(NOW());
SELECT WEEK('2022/12/31');
# 今天的今年中的第几天
SELECT DATEDIFF(NOW(),'2022/01/01');
# 今天之后的第10天是那一天
SELECT ADDDATE(NOW(),10)
# 查David已经入职多少天了
SELECT `FIRST_NAME`,`LAST_NAME`,`HIRE_DATE`,DATEDIFF(NOW(),`HIRE_DATE`)
FROM `t_employees`
WHERE `FIRST_NAME`='David'
字符串查询
语法: SELECT [字符串函数 (参数列表])
| 字符串函数 | 说明 |
|---|---|
| CONCAT(str1,str2,str....) | 将 多个字符串连接 |
| INSERT(str,pos,len,newStr) | 将str 中指定 pos 位置开始 len 长度的内容替换为 newStr |
| LOWER(str) | 将指定字符串转换为小写 |
| UPPER(str) | 将指定字符串转换为大写 |
| SUBSTRING(str,num,len) | 将str 字符串指定num位置开始截取 len 个内容 |
# 字串函数
# 字串拼接
SELECT CONCAT('My','SQL',' ','Easy');
SELECT FIRST_NAME,LAST_NAME,CONCAT(FIRST_NAME,'-',LAST_NAME)
FROM `t_employees`;
# 字串替换 MySQL==>YourSQL
SELECT INSERT('MySQL',1,2,'Your')
# 字串转大写
SELECT UPPER(`FIRST_NAME`) FROM `t_employees`;
# 字串转小写
SELECT LOWER(`FIRST_NAME`) FROM `t_employees`;
# 字串的截取 MySQL==>SQL
# 如果只指定了位置,就是从指定的位置的最后
SELECT SUBSTRING('MySQL',3)
# 如果指定了位置和长度 从指定的位置开始时截取指定长度的字串
SELECT SUBSTRING('MySQL',3,2)
# 查看名字的前三位
SELECT SUBSTRING(`FIRST_NAME`,1,3) FROM `t_employees`;
聚合函数
语法:SELECT 聚合函数(列名) FROM 表名;
| 聚合函数 | 说明 |
|---|---|
| SUM() | 求所有行中单列结果的总和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| COUNT() | 求总行数 |
单列总和
#统计所有员工每月的工资总和
单列平均值
#统计所有员工每月的平均工资
单列最小值
#统计所有员工中月薪最低的工资
总行数
#统计员工总数
#统计有提成的员工人数
SQL代码
# 聚合函数,对一组数据返回一个结果
# 查询本月总共要发多少工资
SELECT SUM(`SALARY`) FROM `t_employees`
# 平均工资
SELECT AVG(`SALARY`) FROM `t_employees`
# 最高工资
SELECT MAX(`SALARY`) FROM `t_employees`
# 最低工资
SELECT MIN(`SALARY`) FROM `t_employees`
# 多少行数据
SELECT COUNT(`SALARY`) FROM `t_employees`
# 可以写到一块
SELECT SUM(`SALARY`) 总和,AVG(`SALARY`) 平均工资,MAX(salary) 最高工资,
MIN(SALARY) 最低工资,COUNT(salary) 人数 FROM `t_employees`
# COUNT 统计行数,如果有主键列,建议count()主键列
SELECT COUNT(`EMPLOYEE_ID`) FROM `t_employees`
SELECT COUNT(*) FROM `t_employees`
SELECT COUNT(1) FROM `t_employees`
分组查询
语法:SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 分组依据(列);
| 关键字 | 说明 |
|---|---|
| GROUP BY | 分组依据,必须在 WHERE 之后生效 |
查询各部门的总人数
#思路:
#1.按照部门编号进行分组(分组依据是 department_id)
#2.再针对各部门的人数进行统计(count)
查询各部门的平均工资
#思路:
#1.按照部门编号进行分组(分组依据department_id)。
#2.针对每个部门进行平均工资统计(avg)。
查询各个部门、各个岗位的人数
#思路:
#1.按照部门编号进行分组(分组依据 department_id)。
#2.按照岗位名称进行分组(分组依据 job_id)。
#3.针对每个部门中的各个岗位进行人数统计(count)
SQL代码
-- 分组查询
-- 查询各部门的总人数
-- 按某个列进行分组,分完组后,一组中只返回一条数据
-- 查询的列只能是分组的列和聚合函数
select `DEPARTMENT_ID`,
count(*) 人数,
sum(salary) 总工资,
max(salary) 最高工资,
avg(salary) 平均工资
from `t_employees`
group by `DEPARTMENT_ID`;
-- 查询各个部门、各个岗位的人数
select `DEPARTMENT_ID`,`JOB_ID`,count(*) 人数
from `t_employees`
group by `DEPARTMENT_ID`,`JOB_ID`;
分组过滤查询
语法:SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 分组列 HAVING 过滤规则
| 关键字 | 说明 |
|---|---|
| HAVING 过滤规则 | 过滤规则定义对分组后的数据进行过滤 |
统计部门的最高工资
#统计60、70、90号部门的最高工资
#思路:
# 1、按部门进行分组
# 2、对分组的结果进行过滤 60、70、90
# 3、显示结果 部门ID,max(salary)
SELECT `DEPARTMENT_ID`
FROM `t_employees`
GROUP BY `DEPARTMENT_ID`
HAVING `DEPARTMENT_ID` IN (60,70,90)
# where ==> group by ==> having
限定查询
在应用中经常用在分页中
SELECT 列名 FROM 表名 LIMIT 起始行,查询行数
| 关键字 | 说明 |
|---|---|
| LIMIT offset_start,row_count | 限定查询结果的起始行和总行数 |
查询前 5 行记录
#查询表中前五名员工的所有信息
查询范围记录
#查询表中从第四条开始,查询 10 行
# 查询前 5 行记录
# 第一个参数:从下标是几的数据开始
# 第二个参数:查询几条数据
select * from `t_employees` limit 0,5
SELECT * FROM `t_employees` LIMIT 5
# 查询第6-10个人
select * from `t_employees` limit 5,5
LIMIT典型应用
分页查询:一页显示 10 条,查询第三页
select * from `t_employees` limit 20,10
查询总结
SQL 语句编写顺序
SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 分组 HAVING 过滤条件 ORDER BY 排序列(asc|desc)LIMIT 起始行,总条数
SQL 语句执行顺序
1.SELECT : 查询各字段的值
2.FROM :指定数据来源表
3.WHERE : 对查询数据做第一次过滤
4.GROUP BY : 分组
5.HAVING : 对分组后的数据第二次过滤
6.ORDER BY : 排序
7.LIMIT : 限定查询结果
子查询(作为条件判断)
SELECT 列名 FROM 表名 Where 条件 (子查询结果)
查询工资大于Bruce 的员工信息
#1.先查询到 Bruce 的工资(一行一列)
SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce';#工资是 6000
#2.查询工资大于 Bruce 的员工信息
SELECT * FROM t_employees WHERE SALARY > 6000;
#3.将 1、2 两条语句整合
SELECT * FROM t_employees WHERE SALARY > (SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce' );
子查询(作为枚举查询条件)
SELECT 列名 FROM 表名 Where 列名 in(子查询结果);
查询与名为'King'同一部门的员工信息
#思路:
#1. 先查询 'King' 所在的部门编号(多行单列)
SELECT department_id
FROM t_employees
WHERE last_name = 'King'; //部门编号:80、90
#2. 再查询80、90号部门的员工信息
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE department_id in (80,90);
#3.SQL:合并
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE department_id in (SELECT department_id cfrom t_employees WHERE last_name = 'King'); #N行一列
工资高于60部门所有人的信息
#1.查询 60 部门所有人的工资(多行多列)
SELECT SALARY from t_employees WHERE DEPARTMENT_ID=60;
#2.查询高于 60 部门所有人的工资的员工信息(高于所有)
select * from t_employees where SALARY > ALL(select SALARY from t_employees WHERE DEPARTMENT_ID=60);
#。查询高于 60 部门的工资的员工信息(高于部分)
select * from t_employees where SALARY > ANY(select SALARY from t_employees WHERE DEPARTMENT_ID=60);
子查询(作为一张表)
SELECT 列名 FROM(子查询的结果集)WHERE 条件;
查询员工表中工资排名前 5 名的员工信息
#思路:
#1. 先对所有员工的薪资进行排序(排序后的临时表)
select employee_id , first_name , salary
from t_employees
order by salary desc
#2. 再查询临时表中前5行员工信息
select employee_id , first_name , salary
from (临时表)
limit 0,5;
#SQL:合并
select employee_id , first_name , salary
from (select employee_id , first_name , salary from t_employees order by salary desc) as temp
limit 0,5;
合并查询(了解)
UNION 联合
合并两张表的结果(去除重复记录)
#合并两张表的结果,去除重复记录
SELECT * FROM t1 UNION SELECT * FROM t2;
合并两张表的结果(保留重复记录)
#合并两张表的结果,不去除重复记录(显示所有)
SELECT * FROM t1 UNION ALL SELECT * FROM t2;
就是把两个表的数据纵向拼接了【两个表的结构得一致】
image-20220725160601378
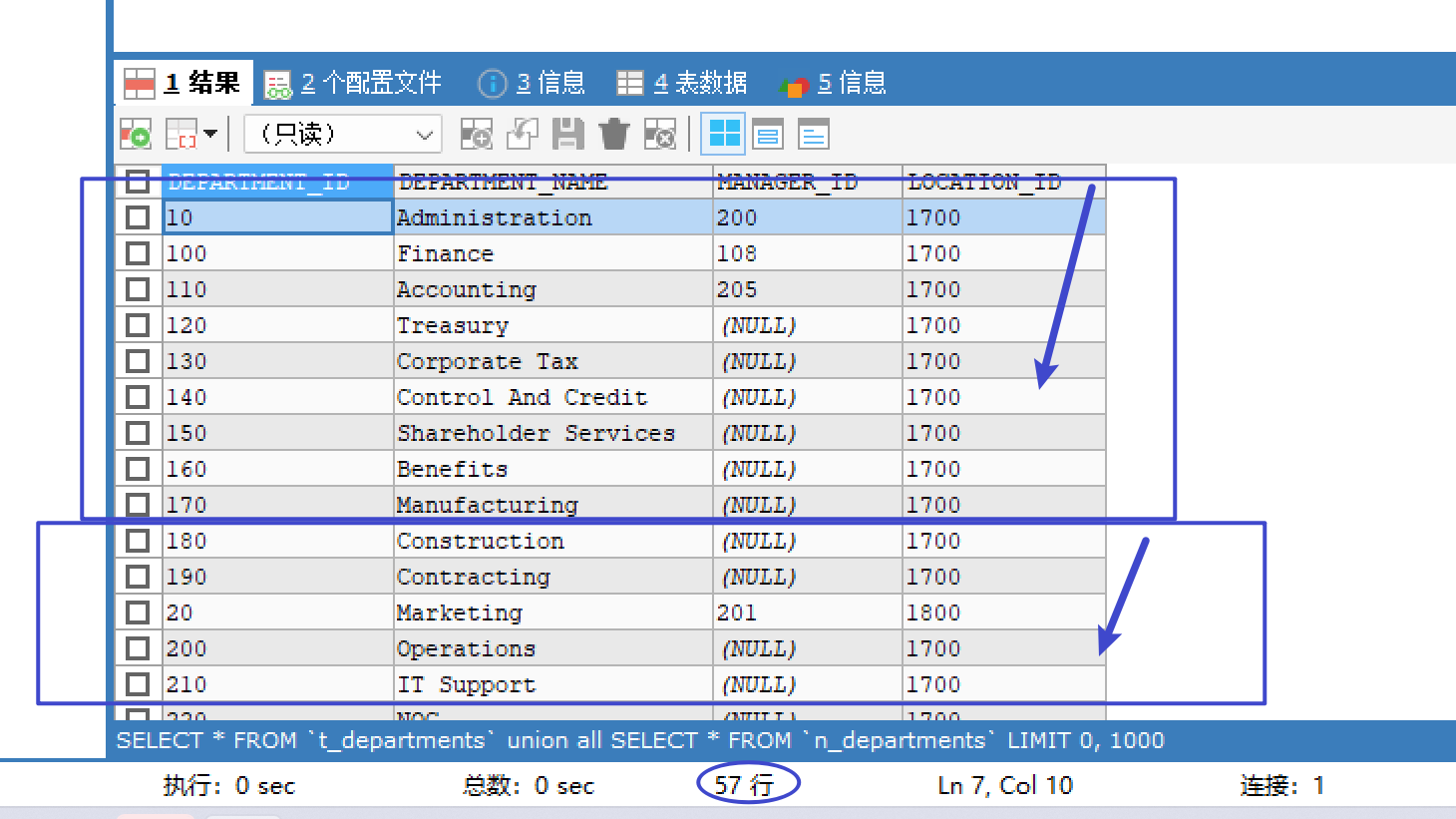
表连接查询
内连接查询(INNER JOIN ON)
# 查询所有员工信息和岗位信息
SELECT e.`EMPLOYEE_ID`,e.`FIRST_NAME`,e.`LAST_NAME`,j.`JOB_ID`,j.`JOB_TITLE`
FROM `t_employees` e
INNER JOIN `t_jobs` j
ON e.`JOB_ID`=j.`JOB_ID`
# 使用where也可以实现inner join的效果
SELECT e.`EMPLOYEE_ID`,e.`FIRST_NAME`,e.`LAST_NAME`,j.`JOB_ID`,j.`JOB_TITLE`
FROM `t_employees` e,`t_jobs` j
WHERE e.`JOB_ID`=j.`JOB_ID`
三表连接查询
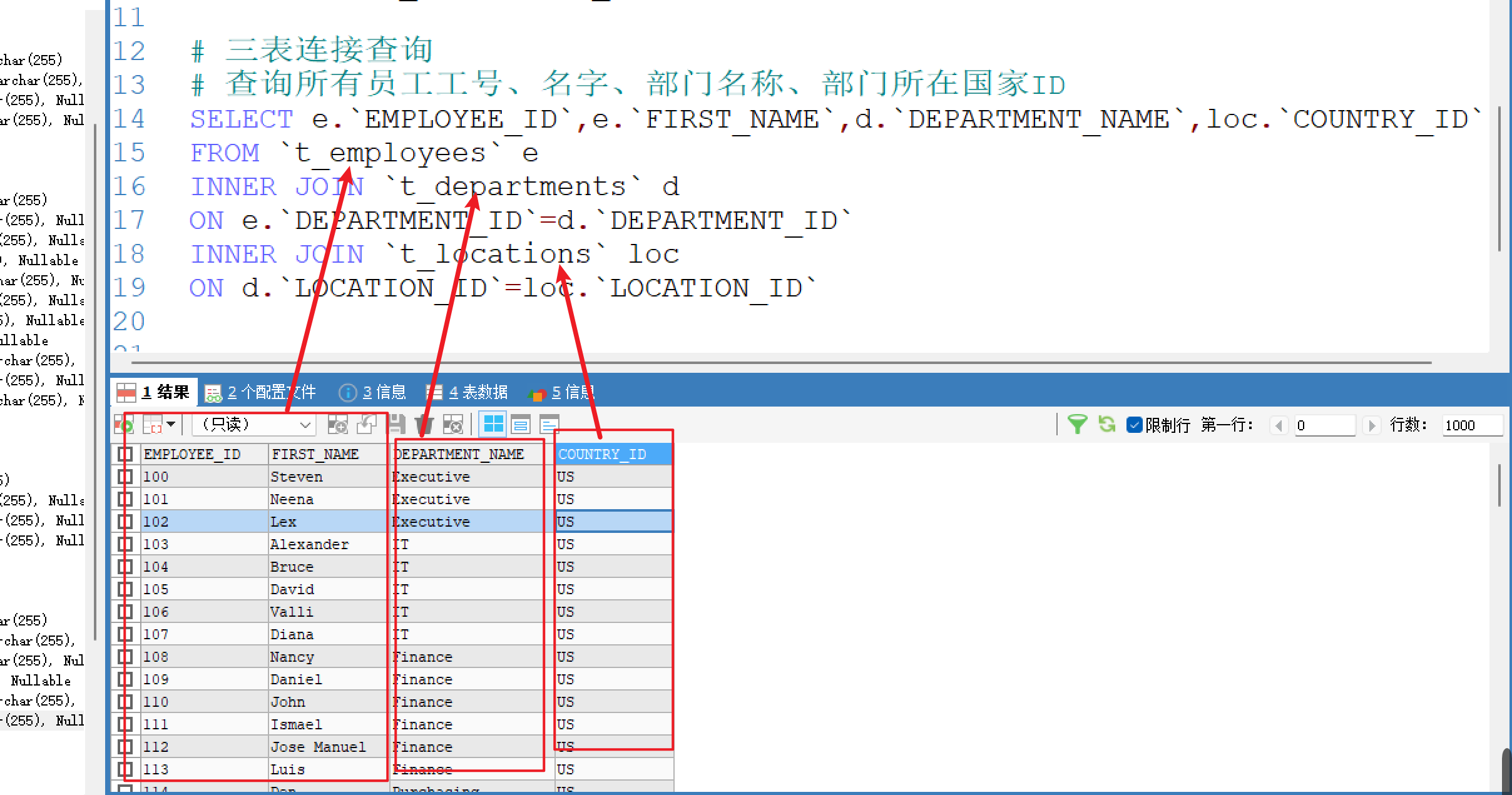
# 三表连接查询
# 查询所有员工工号、名字、部门名称、部门所在国家ID
SELECT e.`EMPLOYEE_ID`,e.`FIRST_NAME`,d.`DEPARTMENT_NAME`,loc.`COUNTRY_ID`
FROM `t_employees` e
INNER JOIN `t_departments` d
ON e.`DEPARTMENT_ID`=d.`DEPARTMENT_ID`
INNER JOIN `t_locations` loc
ON d.`LOCATION_ID`=loc.`LOCATION_ID`
左外连接(LEFT JOIN ON)
#查询所有员工信息,以及所对应的部门名称(没有部门的员工,也在查询结果中,部门名称以NULL 填充)
SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM t_employees e
LEFT JOIN t_departments d
ON e.department_id = d.department_id;
右外连接(RIGHT JOIN ON)
#查询所有部门信息,以及此部门中的所有员工信息(没有员工的部门,也在查询结果中,员工信息以NULL 填充)
SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM t_employees e
RIGHT JOIN t_departments d
ON e.department_id = d.department_id;
主表中的所有数据都要返回
#查询所有员工信息,以及所对应的部门名称
#(没有部门的员工,也在查询结果中,部门名称以NULL 填充)
# 已员工表为主表,主表中的所有数据都要返回,
# 如果员工没有部门就把部门数据填充null值
SELECT e.*,d.`DEPARTMENT_NAME`
FROM `t_employees` e
LEFT JOIN `t_departments` d
ON e.`DEPARTMENT_ID`=d.`DEPARTMENT_ID`
SELECT e.*,d.`DEPARTMENT_NAME`
FROM `t_departments` d
RIGHT JOIN `t_employees` e
ON e.`DEPARTMENT_ID`=d.`DEPARTMENT_ID`
# 查询所有部门信息,以及此部门中的所有员工信息
#(没有员工的部门,也在查询结果中,员工信息以NULL 填充)
SELECT e.*,d.`DEPARTMENT_NAME`
FROM `t_employees` e
RIGHT JOIN `t_departments` d
ON e.`DEPARTMENT_ID`=d.`DEPARTMENT_ID`
SELECT e.*,d.`DEPARTMENT_NAME`
FROM `t_departments` d
LEFT JOIN `t_employees` e
ON e.`DEPARTMENT_ID`=d.`DEPARTMENT_ID`
DML 操作【重点】
新增 insert
修改/更新 update
删除 delete
新增(INSERT)
添加一条信息
#添加一条工作岗位信息
INSERT INTO t_jobs(JOB_ID,JOB_TITLE,MIN_SALARY,MAX_SALARY) VALUES('JAVA_Le','JAVA_Lecturer',2500,9000);
#添加一条员工信息
INSERT INTO `t_employees`
(EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,PHONE_NUMBER,HIRE_DATE,JOB_ID,SALARY,COMMISSION_PCT,MANAGER_ID,DEPARTMENT_ID)
VALUES
('194','Samuel','McCain','SMCCAIN', '650.501.3876', '1998-07-01', 'SH_CLERK', '3200', NULL, '123', '50');
#添加一条工作岗位信息,不指定具体的列
INSERT INTO `t_jobs` VALUES('DEV','开发工程师',10000,30000);
#只添加指定的列
INSERT INTO `t_jobs`(`JOB_ID`,`JOB_TITLE`) VALUES('OPT','运维工程师');
#批量添加,一条SQL可以添加多条数据
INSERT INTO `t_jobs`(`JOB_ID`,`JOB_TITLE`)
VALUES('CEO','首席执行官'),('CTO','技术总监'),('COO','首席运营官');
修改(UPDATE)
UPDATE 表名 SET 列 1=新值 1 ,列 2 = 新值 2,.....WHERE 条件;
修改一条信息
#修改编号为100 的员工的工资为 25000
UPDATE t_employees SET SALARY = 25000 WHERE EMPLOYEE_ID = '100';
#修改编号为135 的员工信息岗位编号为 ST_MAN,工资为3500
UPDATE t_employees SET JOB_ID=ST_MAN,SALARY = 3500 WHERE EMPLOYEE_ID = '135';
#修改数据
#修改编号为100 的员工的工资为 25000
SELECT * FROM `t_employees` WHERE EMPLOYEE_ID=100
UPDATE `t_employees` SET SALARY=25000 WHERE EMPLOYEE_ID=100
# 工资改为30000 提成改为0.5
UPDATE `t_employees` SET SALARY=30000,COMMISSION_PCT=0.5 WHERE EMPLOYEE_ID=100
删除(DELETE)
DELETE FROM 表名 WHERE 条件;
删除一条信息
#删除编号为135 的员工
DELETE FROM t_employees WHERE EMPLOYEE_ID='135';
#删除姓Peter,并且名为 Hall 的员工
DELETE FROM t_employees WHERE FIRST_NAME = 'Peter' AND LAST_NAME='Hall';
清空整表数据(TRUNCATE)
TRUNCATE TABLE 表名;
清空整张表
#清空t_countries整张表
TRUNCATE TABLE t_countries;
#添加一条工作岗位信息,不指定具体的列
INSERT INTO `t_jobs` VALUES('DEV','开发工程师',10000,30000);
#只添加指定的列
INSERT INTO `t_jobs`(`JOB_ID`,`JOB_TITLE`) VALUES('OPT','运维工程师');
#批量添加,一条SQL可以添加多条数据
INSERT INTO `t_jobs`(`JOB_ID`,`JOB_TITLE`)
VALUES('CEO','首席执行官'),('CTO','技术总监'),('COO','首席运营官');
#修改数据
#修改编号为100 的员工的工资为 25000
SELECT * FROM `t_employees` WHERE EMPLOYEE_ID=100
UPDATE `t_employees` SET SALARY=25000 WHERE EMPLOYEE_ID=100
# 工资改为30000 提成改为0.5
UPDATE `t_employees` SET SALARY=30000,COMMISSION_PCT=0.5 WHERE EMPLOYEE_ID=100
# 所有人的工资都降1000倍
UPDATE `t_employees` SET SALARY=SALARY*1000
# 删除编号为135 的员工
SELECT * FROM `t_employees` WHERE EMPLOYEE_ID=135
DELETE FROM `t_employees` WHERE EMPLOYEE_ID=135
# 清空`n_departments`
TRUNCATE TABLE n_departments;
# 删除整个数据库
DROP DATABASE `companydb`;
数据表操作
数据类型
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。对于我们约束数据的类型有很大的帮助
数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| INT | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| DOUBLE | 8 字节 | (-1.797E+308,-2.22E-308) | (0,2.22E-308,1.797E+308) | 双精度浮点数值 |
| DOUBLE(M,D) | 8个字节,M表示长度,D表示小数位数 | 同上,受M和D的约束 DOUBLE(5,2) -999.99-999.99 | 同上,受M和D的约束 | 双精度浮点数值 |
| DECIMAL(M,D) | DECIMAL(M,D) | 依赖于M和D的值,M最大值为65 | 依赖于M和D的值,M最大值为65 | 小数值 |
数值类型详解
mysql数据库设计,其中,对于数据性能优化,字段类型考虑很重要,有关mysql整型bigint、int、mediumint、smallint 和 tinyint的语法介绍,如下:
1、bigint
从 -2^63 (-9223372036854775808) 到 2^63-1 (9223372036854775807) 的整型数据(所有数字),无符号的范围是0到18446744073709551615。一位为 8 个字节。
2、int
一个正常大小整数。有符号的范围是-2^31 (-2,147,483,648) 到 2^31 - 1 (2,147,483,647) 的整型数据(所有数字),无符号的范围是0到4294967295。一位大小为 4 个字节。int 的 SQL-92 同义词为 integer。
3、mediumint
一个中等大小整数,有符号的范围是-8388608到8388607,无符号的范围是0到16777215。 一位大小为3个字节。
4、smallint
一个小整数。有符号的范围是-2^15 (-32,768) 到 2^15 - 1 (32,767) 的整型数据,无符号的范围是0到65535。一位大小为 2 个字节。MySQL提供的功能已经绰绰有余,而且由于MySQL是开放源码软件,因此可以大大降低总体拥有成本。
5、tinyint
有符号的范围是-128 - 127,无符号的范围是 从 0 到 255 的整型数据。一位大小为 1 字节。
日期类型
| 类型 | 大小 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字符 | 定长字符串 char(10) 10个字符 |
| VARCHAR | 0-65535 字节 | 变长字符串 varchar(10) 10个字符 |
| BLOB(binary large object) | 0-65535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65535字节 | 长文本数据 |
- CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
- BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
总结:
常用的数据类型
数值类型: 常用的是int、 bigint、tinyint【-127到128】 【0-255】
时间日期类型:常用的 date 年月日 datetime 年月日时分秒 timestamp 使用数值来保存日期的
字串类型:常用类型是,如果保存不太长的字串varchar【可变长度】如果文本内容非常多可以使用 text
如果表里的字段类型设置为了时间戳类型:
特点:这个字段默认不能为空,并且有个默认值【当前时间】
并且这条数据在更新时,时间戳会自动更新为【当前时间】
数据表的创建(CREATE)
....
列名 数据类型 [约束] //最后一列的末尾不加逗号
)[charset=utf8] //可根据需要指定表的字符编码集
创建表
| 列名 | 数据类型 | 说明 |
|---|---|---|
| subjectId | INT | 课程编号 |
| subjectName | VARCHAR(20) | 课程名称 |
| subjectHours | INT | 课程时长 |
#依据上述表格创建数据表,并向表中插入 3 条测试语句
CREATE TABLE subject(
subjectId INT,
subjectName VARCHAR(20),
subjectHours INT
)charset=utf8;
INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(1,'Java',40);
INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(2,'MYSQL',20);
INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(3,'JavaScript',30);
数据表的修改(ALTER)
ALTER TABLE 表名 操作;
向现有表中添加列
#在课程表基础上添加gradeId 列
ALTER TABLE subject ADD gradeId int;
修改表中的列
#修改课程表中课程名称长度为10个字符
ALTER TABLE subject MODIFY subjectName VARCHAR(10);
删除表中的列
#删除课程表中 gradeId 列
ALTER TABLE subject DROP gradeId;
修改列名
#修改课程表中 subjectHours 列为 classHours
ALTER TABLE subject CHANGE subjectHours classHours int ;
修改表名
#修改课程表的subject 为 sub
ALTER TABLE subject rename sub;
数据表的删除(DROP)
DROP TABLE 表名
删除课程表
#删除课程表
DROP TABLE subject;
约束
- 问题:在往已创建表中新增数据时,可不可以新增两行相同列值得数据?
- 如果可行,会有什么弊端?
- 修改删除的时候同时删了
- 在业务上其实是一条重复的记录
实体完整性约束
表中的一行数据代表一个实体(entity),实体完整性的作用即是标识每一行数据不重复、实体唯一。
主键约束
PRIMARY KEY 唯一,标识表中的一行数据,此列的值不可重复,且不能为 NULL
主键的特点:
唯一:不能重复,只能由一个
且不能为null
#为表中适用主键的列添加主键约束
CREATE TABLE subject(
subjectId INT PRIMARY KEY,#课程编号标识每一个课程的编号唯一,且不能为 NULL
subjectName VARCHAR(20),
subjectHours INT
)charset=utf8;
INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(1,'Java',40);
INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(1,'Java',40);
# Duplicate entry '1' for key 'PRIMARY' 主键重复了,数据添加失败
唯一约束
UNIQUE 唯一,标识表中的一行数据,不可重复,可以为 NULL
#为表中列值不允许重复的列添加唯一约束
CREATE TABLE subject(
subjectId INT PRIMARY KEY,
subjectName VARCHAR(20) UNIQUE,#课程名称唯一!
subjectHours INT
)charset=utf8;
INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(1,'Java',40);
INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(2,'Java',40);
#Duplicate entry 'html' for key 'subjectName' 课程名称已存在
自动增长列
AUTO_INCREMENT 自动增长,给主键数值列添加自动增长。从 1 开始,每次加 1。不能单独使用,和主键配合。一张表最多只能拥有一个自增长
#为表中主键列添加自动增长,避免忘记主键 ID 序号
CREATE TABLE subject(
#课程编号主键且自动增长,会从 1 开始根据添加数据的顺序依次加 1
subjectId INT PRIMARY KEY AUTO_INCREMENT,
subjectName VARCHAR(20) UNIQUE,
subjectHours INT
)charset=utf8;
INSERT INTO subject(subjectName,subjectHours) VALUES('Java',40);#课程编号自动从 1 增长
INSERT INTO subject(subjectName,subjectHours) VALUES('JavaScript',30);#第二条编号为 2
域完整性约束
限制列的单元格的数据正确性。
非空约束
NOT NULL 非空,此列必须有值。
#课程名称虽然添加了唯一约束,但是有 NULL 值存在的可能,要避免课程名称为NULL
CREATE TABLE subject(
subjectId INT PRIMARY KEY AUTO_INCREMENT,
subjectName VARCHAR(20) UNIQUE NOT NULL,
subjectHours INT
)charset=utf8;
INSERT INTO subject(subjectName,subjectHours) VALUES(NULL,40);#error,课程名称约束了非空
默认值约束
DEFAULT 值 为列赋予默认值,当新增数据不指定值时,书写DEFAULT,以指定的默认值进行填充。
#当存储课程信息时,若课程时长没有指定值,则以默认课时 20 填充
CREATE TABLE subject(
subjectId INT PRIMARY KEY AUTO_INCREMENT,
subjectName VARCHAR(20) UNIQUE NOT NULL,
subjectHours INT DEFAULT 20
)charset=utf8;
INSERT INTO subject(subjectName,subjectHours) VALUES('Java',DEFAULT);#课程时长以默认值 20 填充
完整代码
-- 创建表
-- PRIMARY KEY 主键约束
-- AUTO_INCREMENT 自增
-- UNIQUE 唯一约束
CREATE TABLE `subject`(
subjectId INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
subjectName VARCHAR(20) UNIQUE COMMENT '课程名称',
subjectHours INT
)
-- 添加数据 主键是自增的,可以不手动给值
INSERT INTO `subject` VALUE(NULL,'java',20);
INSERT INTO `subject` VALUE(NULL,'mysql',30);
INSERT INTO `subject`(subjectName,subjectHours) VALUES('js',40);
-- subjectName可以有空值
INSERT INTO `subject`(subjectHours) VALUES(50);
-- 创建一个新的表 subjectName增加NOT NULL非空约束
CREATE TABLE `subject2`(
subjectId INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
subjectName VARCHAR(20) UNIQUE NOT NULL COMMENT '课程名称',
subjectHours INT
)
INSERT INTO `subject2` VALUE(NULL,'java',20);
INSERT INTO `subject2` VALUE(NULL,'mysql',30);
INSERT INTO `subject2`(subjectHours) VALUES(40);
-- Field 'subjectName' doesn't have a default value:
-- subjectName这个字段没有默认值,你也没有给值就违背了非空约束
-- 创建一个新的表 课程时长给默认值约束20
CREATE TABLE `subject3`(
subjectId INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
subjectName VARCHAR(20) UNIQUE NOT NULL COMMENT '课程名称',
subjectHours INT DEFAULT 20
)
INSERT INTO `subject3`(subjectName) VALUES('java');
INSERT INTO `subject3`(subjectName,`subjectHours`) VALUES('js',30);
引用完整性约束
外键约束 CONSTRAINT:约束
详解:FOREIGN KEY 引用外部表的某个列的值,新增数据时,约束此列的值必须是引用表中存在的值。
#创建专业表
CREATE TABLE special(
id INT PRIMARY KEY AUTO_INCREMENT,
specialName VARCHAR(20) UNIQUE NOT NULL
)CHARSET=utf8;
#创建课程表(课程表的SpecialId 引用专业表的 id)
CREATE TABLE subject(
subjectId INT PRIMARY KEY AUTO_INCREMENT,
subjectName VARCHAR(20) UNIQUE NOT NULL,
subjectHours INT DEFAULT 20,
specialId INT NOT NULL,
CONSTRAINT fk_subject_specialId FOREIGN KEY(specialId) REFERENCES special(id)
#引用专业表里的 id 作为外键,新增课程信息时,约束课程所属的专业。
)charset=utf8;
#专业表新增数据
INSERT INTO special(specialName) VALUES('Java');
INSERT INTO special(specialName) VALUES('C#');
#课程信息表添加数据
INSERT INTO subject(subjectName,subjectHours,specialId) VALUES('Java',30,1);#专业 id 为 1,引用的是专业表的 Java
INSERT INTO subject(subjectName,subjectHours,specialId) VALUES('C#MVC',10,2);#专业 id 为 2,引用的是专业表的 C#
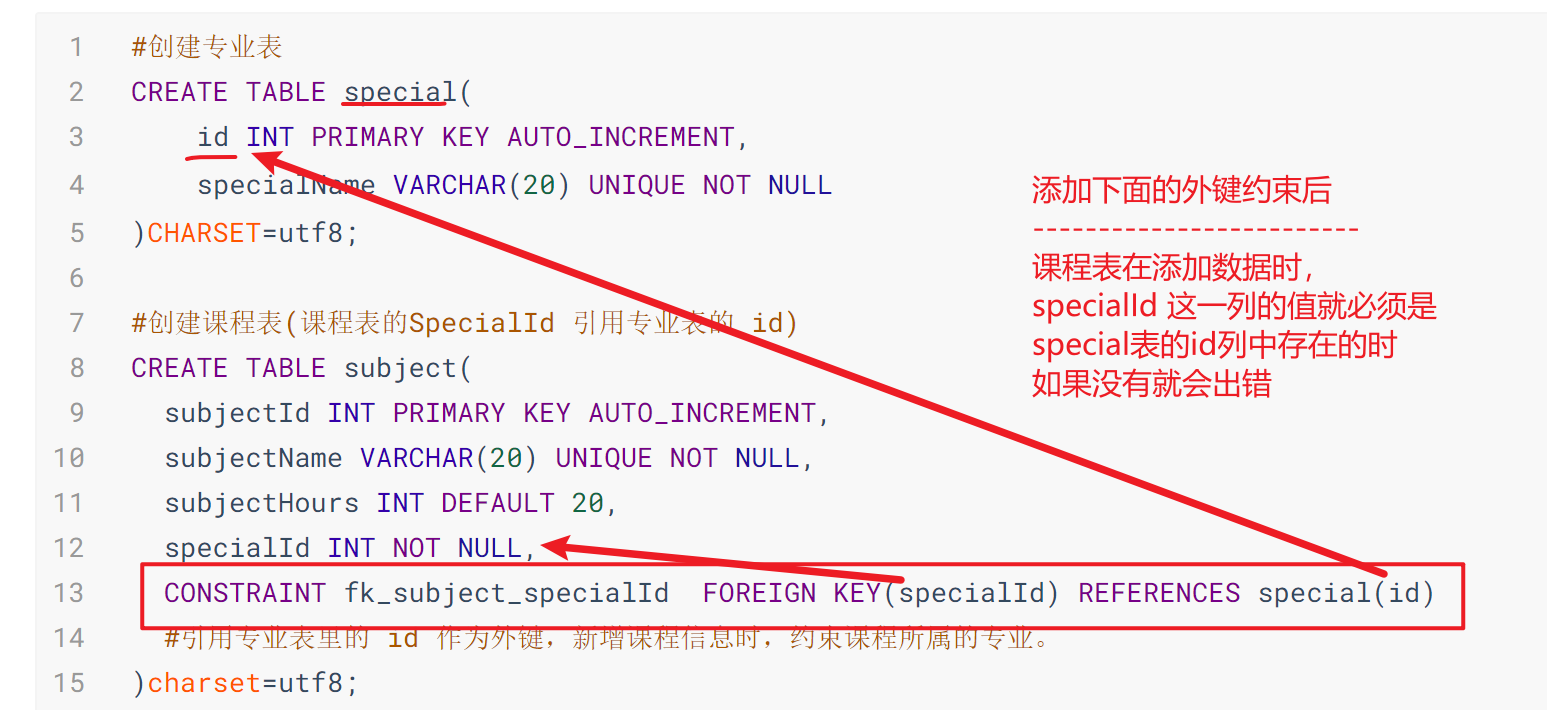
如果是已经存在的表,之前没有设置外键约束,可以通过修改表,添加外键约束
修改表添加新字段
ALTER TABLE `subject` ADD specialId INT NOT NULL
修改表添加约束
ALTER TABLE `subject` ADD
CONSTRAINT fk_subject_specialId FOREIGN KEY(specialId)
REFERENCES `special`(`id`)
约束创建整合
创建带有约束的表。
创建表
| 列名 | 数据类型 | 约束 | 说明 |
|---|---|---|---|
| GradeId | INT | 主键、自动增长 | 班级编号 |
| GradeName | VARCHAR(20) | 唯一、非空 | 班级名称 |
CREATE TABLE Grade(
GradeId INT PRIMARY KEY AUTO_INCREMENT,
GradeName VARCHAR(20) unique NOT NULL
)CHARSET=UTF8;
| 列名 | 数据类型 | 约束 | 说明 |
|---|---|---|---|
| student_id | VARCHAR(50) | 主键 | 学号 |
| Student_name | VARCHAR(50) | 非空 | 姓名 |
| sex | CHAR(2) | 默认填充'男' | 性别 |
| borndate | DATE | 非空 | 生日 |
| phone | VARCHAR(11) | 无 | 电话 |
| GradeId | INT | 非空,外键约束:引用班级表的 gradeid。 | 班级编号 |
CREATE TABLE student(
student_id varchar(50) PRIMARY KEY,
student_name varchar(50) NOT NULL,
sex CHAR(2) DEFAULT '男'
borndate date NOT NULL,
phone varchar(11),
gradeId int not null,
CONSTRAINT fk_student_gradeId FOREIGN KEY(gradeId) REFERENCES Grade(GradeId)
#引用Grade表的GradeId列的值作为外键,插入时约束学生的班级编号必须存在。
);
事务【重点】
模拟转账
生活当中转账是转账方账户扣钱,收账方账户加钱。我们用数据库操作来模拟现实转账。
数据库模拟转账
#A 账户转账给 B 账户 1000 元。
#A 账户减1000 元
UPDATE account SET MONEY = MONEY-1000 WHERE id=1;
#B 账户加 1000 元
UPDATE account SET MONEY = MONEY+1000 WHERE id=2;
模拟转账错误
#A 账户转账给 B 账户 1000 元。
#A 账户减1000 元
UPDATE account SET MONEY = MONEY-1000 WHERE id=1;
#断电、异常、出错...
#B 账户加 1000 元
UPDATE account SET MONEY = MONEY+1000 WHERE id=2;
事务的概念
要么事务内部的多个操作同时成功,要么同时失败!
事务是一个原子操作。是一个最小执行单元。可以由一个或多个SQL语句组成,在同一个事务当中,所有的SQL语句都成功执行时,整个事务成功,有一个SQL语句执行失败,整个事务都执行失败。
事务的边界
事务的原理
数据库会为每一个客户端都维护一个空间独立的缓存区(回滚段),一个事务中所有的增删改语句的执行结果都会缓存在回滚段中,只有当事务中所有SQL语句均正常结束(commit),才会将回滚段中的数据同步到数据库。否则无论因为哪种原因失败,整个事务将回滚(rollback)。
事务的特性
ACID:
表示一个事务内的所有操作是一个整体,要么全部成功,要么全部失败
表示一个事务内有一个操作失败时,所有的更改过的数据都必须回滚到修改前状态
事务查看数据操作时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。
持久性事务完成之后,它对于系统的影响是永久性的。
事务应用
应用环境:基于增删改语句的操作结果(均返回操作后受影响的行数),可通过程序逻辑手动控制事务提交或回滚
事务完成转账
#A 账户给 B 账户转账。
#1.开启事务
# set AutoCommit=1;#开启自动提交
START TRANSACTION;|set AutoCommit=0;#禁止自动提交 那么我们就需要手动提交事务
#2.事务内数据操作语句
UPDATE ACCOUNT SET MONEY = MONEY-1000 WHERE ID = 1;
UPDATE ACCOUNT SET MONEY = MONEY+1000 WHERE ID = 2;
#3.事务内语句都成功了,执行 COMMIT;
#COMMIT;
4.事务内如果出现错误,执行 ROLLBACK;
ROLLBACK;
权限管理
创建用户
CREATE USER 用户名 IDENTIFIED BY 密码
创建一个用户
#创建一个 zhangsan 用户
CREATE USER `zhangsan` IDENTIFIED BY '123';
授权
GRANT ALL ON 数据库.表 TO 用户名;
用户授权
#将 companyDB下的所有表的权限都赋给 zhangsan
GRANT ALL ON companyDB.* TO `zhangsan`;
撤销权限
REVOKE ALL ON 数据库.表名 FROM 用户名
撤销用户权限
#将 zhangsan 的 companyDB 的权限撤销
REVOKE ALL ON companyDB.* FROM `zhangsan`;
删除用户
DROP USER 用户名
删除用户
#删除用户 zhangsan
DROP USER `zhangsan`;
视图
概念
视图,虚拟表,从一个表或多个表中查询出来的表,作用和真实表一样,包含一系列带有行和列的数据。视图中,用户可以使用SELECT语句查询数据,也可以使用INSERT,UPDATE,DELETE修改记录,视图可以使用户操作方便,并保障数据库系统安全。
视图特点
优点
- 简单化,数据所见即所得。
- 安全性,用户只能查询或修改他们所能见到得到的数据。
- 逻辑独立性,可以屏蔽真实表结构变化带来的影响。
缺点
- 性能相对较差,简单的查询也会变得稍显复杂。
- 修改不方便,特变是复杂的聚合视图基本无法修改。
视图的创建
语法:CREATE VIEW 视图名 AS 查询数据源表语句;
创建视图
#创建 t_empInfo 的视图,其视图从 t_employees 表中查询到员工编号、员工姓名、员工邮箱、工资
CREATE VIEW t_empInfo
AS
SELECT EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,SALARY from t_employees;
使用视图
#查询 t_empInfo 视图中编号为 101 的员工信息
SELECT * FROM t_empInfo where employee_id = '101';
视图的修改
方式一:CREATE OR REPLACE VIEW 视图名 AS 查询语句
方式二:ALTER VIEW 视图名 AS 查询语句
修改视图
#方式 1:如果视图存在则进行修改,反之,进行创建
CREATE OR REPLACE VIEW t_empInfo
AS
SELECT EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,SALARY,DEPARTMENT_ID from t_employees;
#方式 2:直接对已存在的视图进行修改
ALTER VIEW t_empInfo
AS
SELECT EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,SALARY from t_employees;
视图的删除
DROP VIEW 视图名
删除视图
#删除t_empInfo视图
DROP VIEW t_empInfo;
视图的注意事项
- 注意:
- 视图不会独立存储数据,原表发生改变,视图也发生改变。没有优化任何查询性能。
- 如果视图包含以下结构中的一种,则视图不可更新
- 聚合函数的结果
- DISTINCT 去重后的结果
- GROUP BY 分组后的结果
- HAVING 筛选过滤后的结果
- UNION、UNION ALL 联合后的结果
- 对视图的修改本质上还是对原表的修改
SQL 语言分类
SQL语言分类
数据查询语言DQL(Data Query Language):select、where、order by、group by、having limit。
数据定义语言DDL(Data Definition Language):create、alter、drop。
数据操作语言DML(Data Manipulation Language):insert、update、delete 。
事务处理语言TPL(Transaction Process Language):commit、rollback 。
数据控制语言DCL(Data Control Language):grant、revoke。
综合练习
数据库表
SELECT REPLACE(UUID(),'-','');使用UUID()函数可以获取唯一不重复的32位的字串
# 创建用户表
create table `user`(
userId int primary key auto_increment,
username varchar(20) not null,
`password` varchar(18) not null,
address varchar(100),
phone varchar(11)
);
#创建分类表
create table category(
cid varchar(32) PRIMARY KEY ,
cname varchar(100) not null #分类名称
);
# 商品表
CREATE TABLE `products` (
`pid` varchar(32) PRIMARY KEY,
`name` VARCHAR(40) ,
`price` DOUBLE(7,2),
category_id varchar(32),
constraint fk_products_category_id foreign key(category_id) references category(cid)
);
#订单表
create table `orders`(
`oid` varchar(32) PRIMARY KEY ,
`totalprice` double(12,2), #总计
`userId` int,
constraint fk_orders_userId foreign key(userId) references `user`(userId) #外键
);
# 订单项表
create table orderitem(
oid varchar(32), #订单id
pid varchar(32), #商品id
num int , #购买商品数量
primary key(oid,pid), #联合主键,订单id和商品id组合起来必须保证全局唯一
constraint fk_orderitem_oid foreign key(oid) references orders(oid),
constraint fk_orderitem_pid foreign key(pid) references products(pid)
);
#-----------------------------------------------
#初始化数据
#用户表添加数据
INSERT INTO USER(username,PASSWORD,address,phone) VALUES('张三','123','北京昌平沙河','13812345678');
INSERT INTO USER(username,PASSWORD,address,phone) VALUES('王五','5678','北京海淀','13812345141');
INSERT INTO USER(username,PASSWORD,address,phone) VALUES('赵六','123','北京朝阳','13812340987');
INSERT INTO USER(username,PASSWORD,address,phone) VALUES('田七','123','北京大兴','13812345687');
#给分类表初始化数据
insert into category values('c001','电器');
insert into category values('c002','服饰');
insert into category values('c003','化妆品');
insert into category values('c004','书籍');
#给商品表初始化数据
insert into products(pid,name,price,category_id) values('p001','联想',5000,'c001');
insert into products(pid,name,price,category_id) values('p002','海尔',3000,'c001');
insert into products(pid,name,price,category_id) values('p003','雷神',5000,'c001');
insert into products(pid,name,price,category_id) values('p004','JACK JONES',800,'c002');
insert into products(pid,name,price,category_id) values('p005','真维斯',200,'c002');
insert into products(pid,name,price,category_id) values('p006','花花公子',440,'c002');
insert into products(pid,name,price,category_id) values('p007','劲霸',2000,'c002');
insert into products(pid,name,price,category_id) values('p008','香奈儿',800,'c003');
insert into products(pid,name,price,category_id) values('p009','相宜本草',200,'c003');
insert into products(pid,name,price,category_id) values('p010','梅明子',200,null);
#添加订单
insert into orders values('o6100',18000.50,1);
insert into orders values('o6101',7200.35,1);
insert into orders values('o6102',600.00,2);
insert into orders values('o6103',1300.26,4);
#订单详情表
insert into orderitem values('o6100','p001',1),('o6100','p002',1),('o6101','p003',1);
综合练习1-【多表查询】
查询所有用户的订单
SELECT o.oid,o.totalprice, u.userId,u.username,u.phone
FROM orders o INNER JOIN USER u ON o.userId=u.userId;
查询用户id为 1 的所有订单详情
SELECT o.oid,o.totalprice, u.userId,u.username,u.phone ,oi.pid
FROM orders o INNER JOIN USER u ON o.userId=u.userId
INNER JOIN orderitem oi ON o.oid=oi.oid
where u.userid=1;
综合练习2-【子查询】
查看用户为张三的订单
SELECT * FROM orders WHERE userId=(SELECT userid FROM USER WHERE username='张三');
查询出订单的价格大于800的所有用户信息。
SELECT * FROM USER WHERE userId IN (SELECT DISTINCT userId FROM orders WHERE totalprice>800);
综合练习3-【分页查询】
查询所有订单信息,每页显示5条数据
#查询第一页
SELECT * FROM orders LIMIT 0,5;